
Lecture recording here.
This week we look at two responsible AI patterns: the explainable predictions pattern and the fairness lens pattern. The explainable predictions pattern applies model explainability techniques to understand how and why models make predictions and improve user trust in machine learning systems. The fairness lens pattern uses tools to identify bias in datasets before training and evaluate trained models through a fairness lens to ensure model predictions are equitable across different groups of users and different scenarios.
In this week we also take a look at a general approach to design patterns.
| Explainable Predictions Pattern | Interpretable vs Explainable Machine Learning |
Assignment 6 - Investigation of Design Patterns for Machine Learning
The Rationale
The Explainable Predictions design pattern aims to provide transparent and interpretable explanations for the predictions or decisions made by machine learning models. As machine learning models are increasingly used in critical domains such as healthcare, finance, or autonomous systems, it becomes crucial to ensure trust and transparency in the decision-making process. Machine learning models are black boxes in general. But having a clear understanding of the model behavior is very important to diagnose the errors and to identify potential biases to decide if they can be employed. Introducing explainability in machine learning is a major factor in Responsible AI. Hence, the key idea of this pattern is to interpret the machine learning models to understand why and how the model made the predictions in a certain way.
A slightly similar implementation of the explainable predictions is the Linux error coding system. Typically in Linux when a system error occurs, an error code is assigned to the system global variable errno. These codes are know to the software but are not human readable. See Standard Linux Error Codes. A human readable form of the codes can be obtained by calling the global function strerror passing through errno as an argument. This is a human readable text representation of the error.
The UML
Here is a UML diagram for the explainable predictions pattern:
+------------------+ | ExplanableModel | +------------------+ | - Model | +------------------+ | + explain() | | + predict() | +------------------+In this UML diagram, the Explainable Predictions Design Pattern consists of a single component:
Code Example - Explainable Predictions
Below is a simple code example with the explainable predictions pattern:
C++: ExplainablePredictions.cpp.
C#: ExplainablePredictions.cs.
Java: ExplainablePredictions.java.
Python: ExplainablePredictions.py.
Common Usage
The Explainable Predictions design pattern is gaining importance in the software industry as the need for interpretability and transparency in machine learning models increases. Here are some common usages of the Explainable Predictions design pattern in industry:
Code Problem - Complex Predictions
The PredictionModel abstract base class has three pure virtual methods: loadModel, predict, and explain. These methods are responsible for loading the model, making predictions, and providing explanations, respectively. The PredictionModel abstract base class includes two additional pure virtual methods: preprocessData and postprocessResults. These methods represent the steps for preprocessing the data before prediction and post-processing the prediction results, respectively.
The ConcretePredictionModel class is updated to implement these additional methods. It performs data preprocessing before making the prediction and performs post-processing on the prediction results.
The ExplainablePredictionModel wrapper class is also updated to delegate the preprocessData and postprocessResults methods to the wrapped model, similar to the existing delegation for other methods.
In the main function, we demonstrate the complete prediction workflow using the explainableModel. We load
the model, preprocess the data, make a prediction, explain the prediction, and post-process the prediction results.
PredictionModel.h,
ConcretePredictionModel.h,
ExplainablePredictionModel.h,
ComplexPredictions.cpp.
Code Problem - Linear Regression Explainer
The following code implements a linear regression model and an explainer class to provide explanations for predictions.
MLModel.h,
ExplainablePrediction.h,
LinearRegressionModel.h,
LinearRegressionExplainer.h,
LRExplainerMain.cpp.
The Rationale
The Fairness Lens design pattern is about making sure that machine-learning models behave fairly toward different groups of people, especially when the model influences important decisions (loans, hiring, policing, healthcare, school admissions, etc.). The Fairness Lens ML design pattern exists because models often inherit human biases in the data, so fairness cannot be assumed and must be explicitly measured across different demographic groups using definitions appropriate to the domain. It prevents real-world harm and maintains trust by ensuring no group is systematically disadvantaged, and it treats fairness as an ongoing responsibility throughout data collection, model training, deployment, and drift monitoring. The pattern also aligns ML systems with ethical expectations and growing regulatory requirements in sectors like finance, healthcare, employment, and public services.
The UML
Here is a UML for the fairness lens design pattern where MLSystem uses a Model and a FairnessLens,
FairnessLens runs one or more FairnessMetrics on different Groups, and
Results go into a FairnessReport with per-group MetricResults:
Code Example - Fairness Lens
The below code shows a tiny version of the Fairness Lens idea. We have a Model that makes basic predictions by checking
whether a score is above 0.5. Two groups (Group A and Group B) each have a few scores, and the FairnessMetric
calculates how many of those scores the model predicts as positive. The FairnessLens then applies this metric to each group
and prints the results. Because Group A has mostly high scores, it receives more positive predictions than Group B,
which has only low scores. This difference illustrates how a fairness check can reveal unequal outcomes between groups, even in a very simple system.
C++: FairnessLens.cpp,
C#: FairnessLens.cs,
Java: FairnessLensSimple.java,
Python: FairnessLens.py
Common Usage
Below are some common usages of the Explainable Predictions design pattern in industry.
Finance and Banking: In finance, banks and lenders use fairness lenses to check whether their loan approval, credit scoring, and fraud detection models treat different groups (such as age, gender, or neighborhood) fairly, and to prove to regulators that the models do not unfairly deny credit or set worse terms for protected groups.
Hiring and HR: In hiring and human resources, companies apply fairness checks to resume screeners, interview scorers, and job-matching tools to see if candidates from different backgrounds get similar chances, and to adjust or redesign models that might quietly favor one group over another.
Healthcare and Medical AI: In healthcare, hospitals and health-tech companies use fairness lenses to compare model accuracy and treatment recommendations across groups (for example different ages, genders, or skin tones) so that diagnostic tools and risk scores do not systematically miss or mistreat certain patients.
Public Sector and Government Services: Governments and public agencies use fairness evaluations for algorithms that support decisions about benefits, housing, policing, and immigration, checking whether people from different communities receive similar treatment and changing or limiting models that create unfair outcomes.
Online Platforms and Advertising: Large online platforms apply fairness lenses to recommendation systems, search ranking, and ad delivery, to see whether certain groups or creators are being shown less often or given fewer opportunities, and to adjust ranking or targeting rules when they detect unfair patterns.
Insurance: Insurance companies use fairness checks to analyze pricing and risk models for auto, home, or life insurance so that people with similar real-world risk are treated similarly, and to make sure their algorithms do not indirectly use sensitive attributes like gender or race to set higher premiums.
Retail and Customer Analytics: In retail, fairness lenses are used to inspect personalized pricing, promotions, and customer scoring models so that customers in certain locations, income levels, or demographic groups are not consistently offered worse deals or poorer service compared to others.
AI Platforms and Tools Vendors: Big technology companies that provide ML tools and cloud services build fairness-lens components (such as fairness metrics, dashboards, and reports) into their platforms so that their customers—banks, hospitals, retailers, and governments—can routinely test and document the fairness of the models they deploy.
Code Problem - Fairness ML Auditor
Here is a UML for the fairness machine learning auditor:
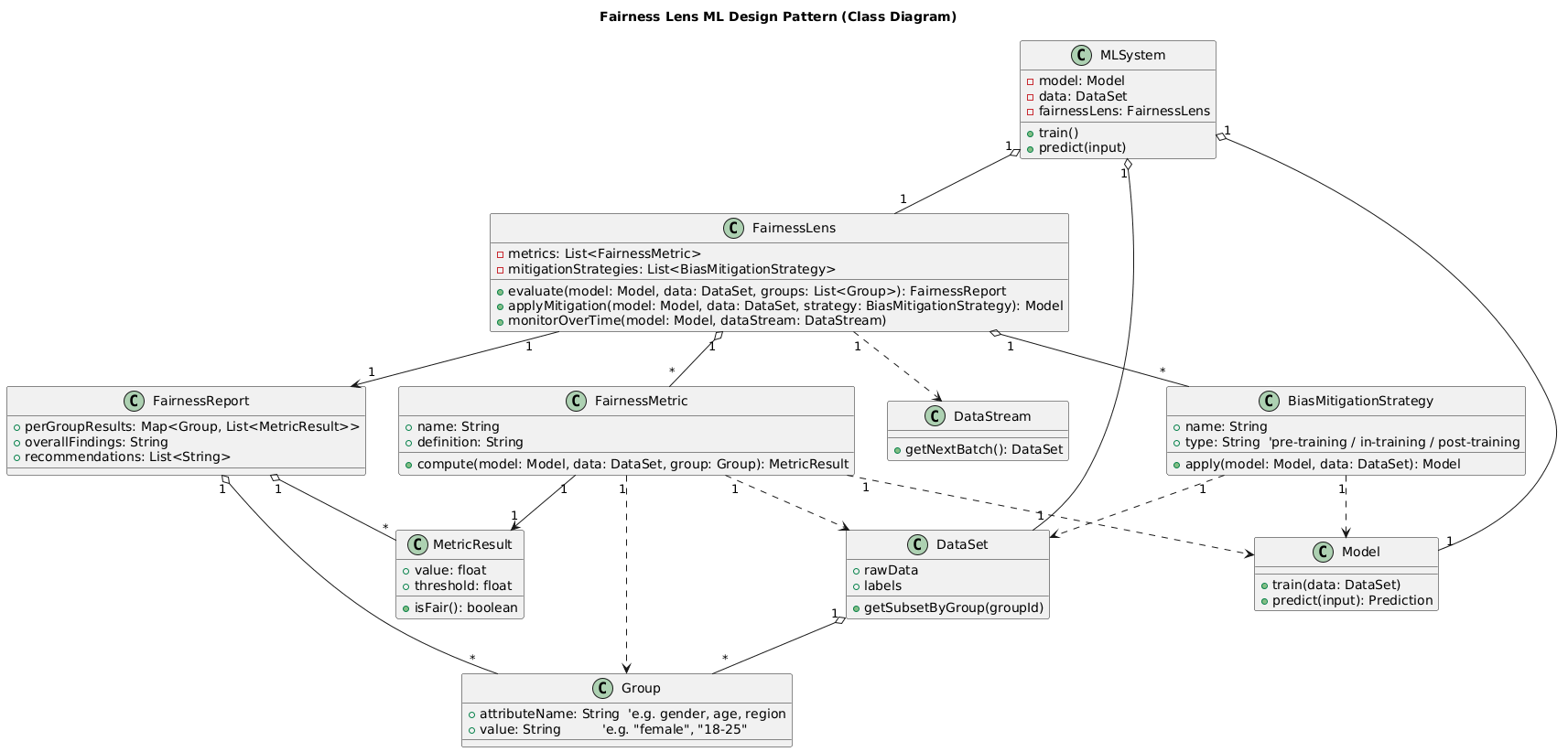
Here is a more detailed explanation of each component:
Code that demonstrates the main ideas from the UML (MLSystem, DataSet, Model, FairnessLens, FairnessMetric, BiasMitigationStrategy, FairnessReport, Group, DataStream, MetricResult)
can be seen below:
BasicDataTypes.h; the structure types for Group, Metric Result and DataPoint,
DataSet.h, the DataSet class,
Model.h, the Model class,
FairnessMetric.h, the FairnessMetric class,
DemographicParityMetric.h, the DemographicParityMetric class,
BiasMitigationStrategy.h, the BiasMitigationStrategy class,
ThresholdAdjustmentStrategy.h, the ThresholdAdjustmentStrategy class,
FairnessReport.h, the FairnessReport class,
DataStream.h, the DataStream class,
FairnessLens.h, the FairnessLens class,
MLSystem.h, the MLSystem class,
FairMLAuditor.cpp, the main function.
This concludes our study of design patterns, both standard and specific to machine learning. As we have studied them,
we notice a common theme in all of them. On the one hand is an interface to some concrete components (or several interfaces
to several sets of concrete components), and on the other hand is a manager or director (or server or publisher) of some sort
to these components. There could even be several managers/directors/servers/publishers accessible through
their own interfaces. See the diagram below:
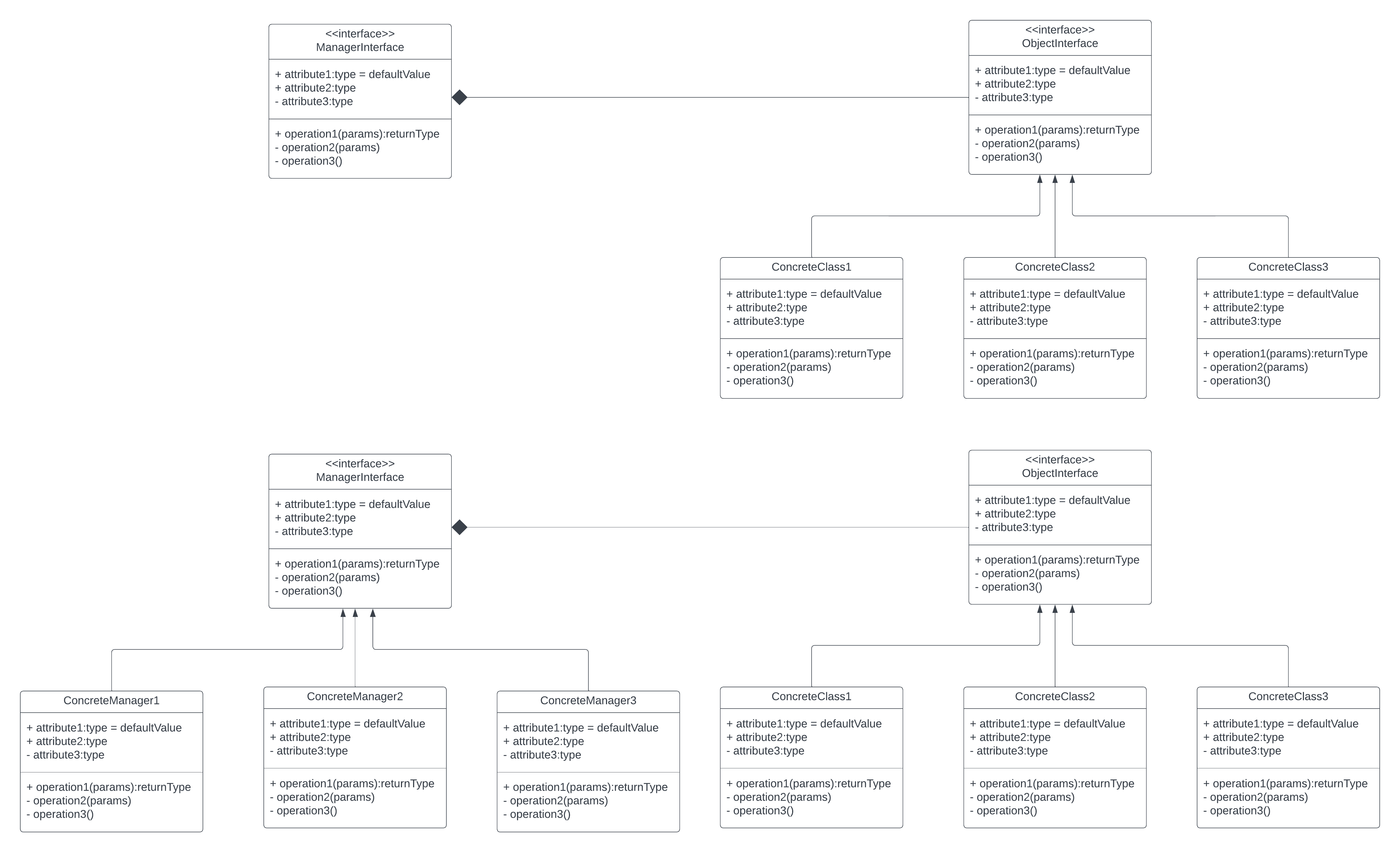
Compare the above generalization to our standard design patterns. The UMLs can be seen at: