The Workflow Pipeline design pattern typically consists of the following components:
Lecture recording here.
Lab recording here.
We look at three more reproducibility patterns this week. This week we look at the the workflow pipeline pattern, the feature store design pattern and the model versioning pattern. The workflow pipeline pattern makes each step of the workflow a separate, containerized service that can be chained together to make a pipeline that can be run with a single call. The feature store design pattern ensures that features used for machine learning models can be consistently and accurately reproduced. This pattern is essential for maintaining the reliability and consistency of ML models over time. The model versioning pattern deploys a changed model as a microservice with a different endpoint to achieve backward compatibility for deployed models.
| The Workflow Pipeline Pattern | ML Design Patterns (2:19-4:53) |
| The Feature Store Pattern | What is a Feature Store for Machine Learning? |
| Machine Learning Design Patterns (11:15-14:35) | |
| The Model Versioning Pattern | Machine Learning Design Patterns | Dr Ebin Deni Raj (1:32:30-1:44:05) |
Assignment 6 - Investigation of Design Patterns for Machine Learning
The Rationale
The Workflow Pipeline design pattern is a software design concept that aims to streamline the processing of a series of sequential steps or tasks in a system. It provides a structured and efficient approach for orchestrating complex workflows, often involving data processing or batch jobs. Many systems involve the execution of a series of tasks or steps that need to be performed in a specific order. The Workflow Pipeline pattern provides a structured and organized way to define, manage, and execute these sequential tasks. It ensures that the tasks are processed in a predefined order, allowing for efficient and controlled execution.
The UML
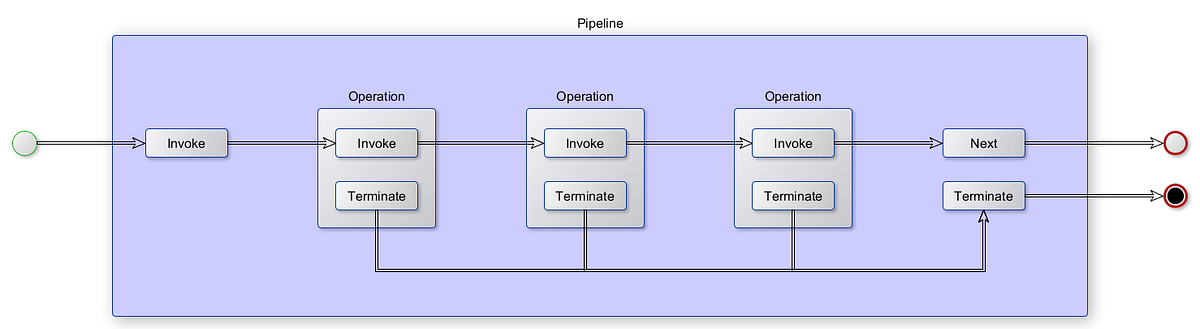
Here is a UML diagram for the workflow pipeline pattern:
The Workflow Pipeline design pattern typically consists of the following components:
Code Example - Workflow Pipeline
Below is a simple code example with the workflow pipeline pattern:
C++: WorkflowPipeline.cpp.
C#: WorkflowPipelineMain.cs.
Java: WorkflowPipelineMain.java.
Python: WorkflowPipeline.py.
Common Usage
The Workflow Pipeline design pattern, also known as the Pipeline pattern or the Pipes and Filters pattern, is a popular design pattern in the software industry. It is commonly used in various domains and scenarios to process and transform data in a series of sequential steps or stages. Here are some common usages of the Workflow Pipeline design pattern:
Code Problem - Data Pipeline
In this example, we have a base class Step representing the individual steps in the workflow pipeline. We have
concrete implementations of the steps:
DataPreparationStep, FeatureExtractionStep, ModelTrainingStep,
and PredictionStep. Each step implements the execute method to perform its specific tasks.
The WorkflowPipeline class represents the pipeline itself. It has a collection of steps and provides methods to add steps to the pipeline and execute the pipeline.
In the main function, we create an instance of the WorkflowPipeline and instances of the concrete steps. We add
the steps to the pipeline using the addStep method. Finally, we execute the pipeline using the execute method.
Step.h,
DataPreparationStep.h,
FeatureExtractionStep.h,
ModelTrainingStep.h,
PredictionStep.h,
WorkflowPipeline.h,
DataPipeline.cpp.
Code Problem - Image Pipeline
The image pipeline loads an image, pre-processes the image, extracts features from the image, trains a model, evaluates the model,
and deploys the model. The code can be seen below.
Image.h,
ImageLoader.h,
ImagePreprocessor.h,
FeatureExtractor.h,
ModelTrainer.h,
ModelEvaluator.h,
ModelDeployer.h,
MLWorkflowPipeline.h,
ImagePipelineMain.cpp.
Code Problem - Second Image Pipeline
This image pipeline is similar to the above. It loads an image, preprocesses the image, extracts CNN (convolutional neural network)
features from the image, trains a CNN model, applies transfer learning, tunes hyperparameters, evaluates the model,
and deploys the model.
Image.h,
ImageLoader.h,
ImagePreprocessor.h,
CNNFeatureExtractor.h,
CNNModelTrainer.h,
TransferLearning.h,
HyperparameterTuner.h,
ModelEvaluator.h,
ModelDeployer.h,
MLWorkflowPipeline.h,
Image2PipelineMain.cpp.
The Feature Store design pattern simplifies the management and reuse of features across projects by decoupling the feature creation process from the development of models using those features. A feature store is a central place to store, update, and serve the input data (features) that machine-learning models use.
The Rationale
Good feature engineering is crucial for the success of many machine learning solutions. However, it is also one of the most time-consuming parts of model development. Some features require significant domain knowledge to calculate correctly, and changes in the business strategy can affect how a feature should be computed. To ensure such features are computed in a consistent way, it's better for these features to be under the control of domain experts rather than ML engineers.
The UML
The following is a basic UML diagram of the feature store design pattern.
+-----------------------------------------------+
| Raw Data Source |
| - Collect data from various sources |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Ingestion Layer |
| - Ingest and store raw data |
| - Ensure immutability |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Transformation Engine |
| - Apply transformations to data |
| - Ensure transformations are deterministic |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Feature Store Layer |
| - Store transformed features |
| - Version control for features |
| - Ensure feature immutability |
| - Track feature lineage |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Feature Serving Interface |
| - Provide features for training and inference|
| - Ensure consistent access to feature versions|
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Machine Learning Model Training |
| - Retrieve versioned features |
| - Ensure reproducible training process |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Model Serving and Deployment |
| - Deploy trained models |
| - Use versioned features for prediction |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Monitoring and Feedback Loop |
| - Monitor model performance |
| - Collect feedback for feature improvement |
+-----------------------------------------------+
Raw Data Source:
Collects data from various sources.Code Example - Feature Store
Below is a simple example of using the feature store design pattern for a machine learning workflow. In this
example, we'll create a basic feature store to manage and retrieve features for training and inference.
C++: FeatureStore.cpp.
C#: FeatureStore.cs.
Java: FeatureStore.java,
FeatureStoreMain.java.
Python: FeatureStore.py.
Common Usage
The feature store design pattern offers a centralized repository for storing, sharing, and managing features. Here are some common usages:
Code Problem - Predictions based on Features
The following code focuses on creating a feature store, adding features, and using these features for predictions:
MultiFeature.cpp.
The FeatureStore class manages feature generators.
The addFeature() method adds a feature generator.
The getFeatures() method retrieves features for a single data point.
The getBatchFeatures() method retrieves features for a batch of data points.
The following example feature generators compute features from a data point: sumFeature(), meanFeature(), and maxFeature.
The main function defines a batch of data points, initializes the feature store and adds feature generators, retrieves features for the data batch,
defines model coefficients and intercept,
initializes the linear regression model and sets feature indexes, and
performs batch predictions and outputs the results.
The Rationale
The Model Versioning Pattern is a software design concept that focuses on managing and evolving machine learning models over time. Machine learning models are typically developed through an iterative process of training, evaluation, and refinement. As new data becomes available or new insights are gained, models need to be updated and improved. The Model Versioning Pattern enables the management of different versions of the model, allowing for easy tracking, comparison, and deployment of new iterations. Model Versioning means keeping track of every version of your machine-learning model, just like software versions (v1, v2, v3...).
The UML
Here is a UML diagram for the model versioning pattern:
+------------------+ | ModelVersion | +------------------+ | - Version Number | | - Model | | - Training Data | +------------------+ | + train() | | + predict() | +------------------+In this UML diagram, the Model Versioning Design Pattern consists of a single component:
Code Example - Model Versioning
Below is a simple code example with the model versioning pattern:
C++: ModelVersioning.cpp.
C#: ModelVersioning.cs.
Java: ModelVersioning.java.
Python: ModelVersioning.py.
Common Usage
The Model Versioning pattern is commonly used in the software industry to manage and control the deployment, usage, and evolution of machine learning models and other types of models. Here are some common usages of the Model Versioning pattern:
Code Problem - Improved Model Versioning
In the main function, we create instances of ModelVersion1, ModelVersion2, and ModelVersion3. We register these model versions with the ModelVersionManager by calling the registerModelVersion method. We then demonstrate loading and prediction using specific model versions.
Later in the example, we create improved versions of Model Version 2 and Model Version 3, represented by ModelVersion2Improved and ModelVersion3Improved. We register these improved model versions with the manager, effectively replacing the previous versions.
Finally, we again demonstrate loading and prediction using the improved model versions.
ModelVersion.h,
ModelVersion1.h,
ModelVersion2.h,
ModelVersion3.h,
ModelVersionManager.h,
ModelVersionManager.cpp,
ImprovedModelVersioning.cpp.
Code Problem - Algorithm Models
The following code represents a scenario where you have multiple algorithms for the same task, and you want to version each
algorithm independently. We'll use a factory pattern for creating instances of models, and each model will have its own
versioning. Additionally, we'll introduce a model manager to coordinate the training and prediction processes.
MLModel.h,
VersionedMLModel.h,
DecisionTreeModel.h,
RandomForestModel.h,
ModelFactory.h,
ModelManager.h,
AlgorithmModelMain.cpp.
Below are examples of standard design patterns applied to machine learning problems. These
implement the command pattern, the observer pattern, and the strategy pattern.
CommandML.cpp,
ObserverML.cpp and
StrategyML.cpp.