Lecture recording here.
Lab recording here.
This week we will look at another pattern that modifies model training: the hyperparameter tuning pattern. The hyperparameter tuning pattern inserts the training loop into an optimization method to find the optimal set of model hyperparameters.
We will also look at two resilience patterns: stateless serving function and batch serving. The stateless serving function pattern exports the machine learning model as a stateless function so that it can be shared by multiple clients in a scalable way. This is because production machine learning systems must be able to synchronously handle thousands to millions of prediction requests per second. The batch serving resilience design pattern focuses on ensuring the reliability and fault tolerance of batch processing systems. This pattern is particularly important in scenarios where large volumes of data are processed in scheduled batches, and any failure can result in significant delays or data loss.
| The Hyperparameter Tuning Pattern | Deep Learning Design Patterns - Jr Data Scientist - Part 6 - Hyperparameter Tuning |
| Hyperparameter Tuning in Practice | |
| The Stateless Serving Function Pattern | Machine Learning Design Patterns | Google Executive | Investor | Meet the Author (What is your favourite design pattern 7:37-10:25) |
Assignment 5 - Multimodal Input: An Autonomous Driving System
A Machine Learning model is defined as a mathematical model with a number of parameters that need to be learned from the data. By training a model with existing data, we are able to fit the model parameters. However, there is another kind of parameter, known as Hyperparameters, that cannot be directly learned from the regular training process. They are usually fixed before the actual training process begins. These parameters express important properties of the model such as its complexity or how fast it should learn.
Hyperparameter tuning patterns are machine learning design patterns that aim to improve model performance by systematically adjusting the parameters that govern the training process, rather than the parameters learned by the model itself. Hyperparameters control aspects such as learning rate, batch size, regularization strength, number of layers or units, and optimizer type. These patterns focus on finding optimal configurations that lead to better generalization and faster convergence.
Hyperparameters heavily influence how a model learns. Tuning these correctly can dramatically improve accuracy and robustness:
For more information see Hyperparameter Tuning - Brief Theory and What you won't find in the HandBook.
The Rationale
The rationale behind the Hyperparameter Tuning Design Pattern is to systematically explore different combinations of hyperparameter values to identify the configuration that produces the best results. By tuning the hyperparameters, we aim to improve the model's performance, generalization, ability, and robustness.
The UML
Here is the UML diagram for the hyperparameter tuning design pattern:
---------------------------------- | Hyperparameter Tuning | | Design Pattern | ---------------------------------- | | | + Define hyperparameters | | + Define search space | | + Define evaluation metric | | + Select tuning strategy | | + Train and evaluate models | | + Select best hyperparameters | | + Test the model | ----------------------------------The hyperparameter tuning design pattern usually involves the following steps:
Code Example - Hyperparameter Tuning
In this program, we demonstrate each step of the Hyperparameter Tuning Design Pattern.
We define the hyperparameters (learningRate, numHiddenUnits, regularizationStrength) in Step 1.
We define the search space for each hyperparameter (learningRates, hiddenUnits, regularizationStrengths) in Step 2.
The evaluation metric is the mean squared error (MSE) in this example, defined as bestMetric in Step 3.
We use nested loops to iterate over the search space of each hyperparameter in Step 4, representing the tuning strategy (in this case, grid search).
Within the loops, we train and evaluate the model using the current hyperparameters in Step 5. The evaluation metric (MSE) is calculated by the trainAndEvaluateModel function.
We select the best hyperparameters based on the metric value in Step 6. If the current metric is better than the previous best, we update the best hyperparameters and metric.
Finally, in Step 7, we print the best hyperparameters and the corresponding metric.
C++: Tuning.cpp.
C#: Tuning.cs.
Java: Tuning.java.
Python: Tuning.py.
Common Usage
The hyperparameter tuning pattern is widely used in the software industry for optimizing the performance of machine learning models and algorithms. The following are some common usages of the hyperparameter tuning pattern:
Code Problem - F1 Score
This code demonstrates the generation of the F1 score using the hyperparameter tuning design pattern. Here's a step-by-step explanation of the code:
Code Example - Support Vector Machine Classification
Below is a complex example of the Hyperparameter Tuning Design Pattern using a hypothetical scenario of a support vector machine (SVM) for classification:
MLModel.h,
SVMClassifier.h,
HyperparameterTuningStrategy.h,
RandomSearchStrategy.h,
GridSearchStrategy.h,
HyperparameterTuningContext.h,
SVMMain.cpp.
The Rationale
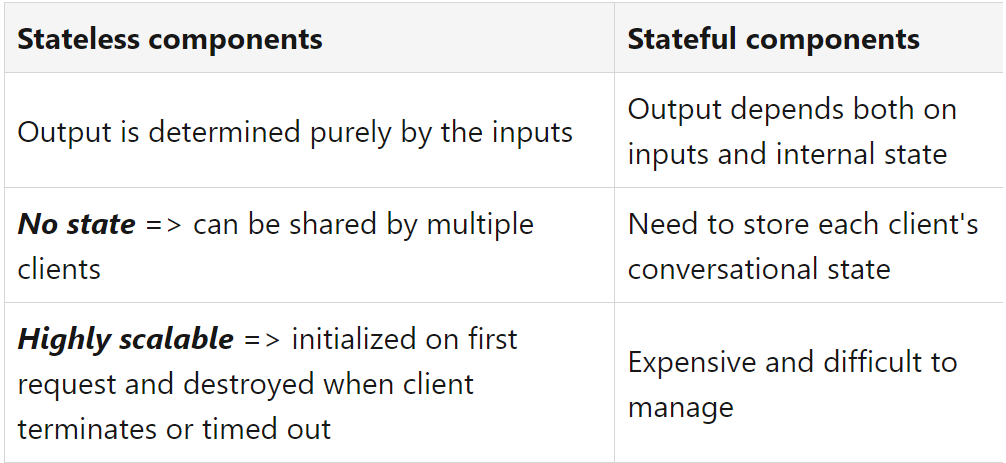
The rationale behind the stateless serving function design pattern is to enable scalable and efficient handling of incoming requests in a distributed computing environment. In this pattern, each request is treated independently, and the server functions do not maintain any state or store any context about previous requests. Instead, they focus solely on processing the current request and generating a response.
When we implement the stateless design pattern, we create classes and objects that
do not retain state changes. In this approach, each use of the object, as an
example, uses the object in its organic form. In our context, state refers to
the values of the object's variables. So, there is no definitive list of states.
The state of an object is specific to a moment in time.
Using this design pattern, we can have a production ML system synchronously handle
millions of prediction requests per second.
Statelessness enhances resilience by:
For a discussion on stateful vs stateless, see RedHat: Stateful vs stateless.
The UML
Here is the UML diagram for the stateless serving function pattern:
+-----------------+
| Application |
+-----------------+
| + serve(request)|
+-----------------+
|
V
+--------------------+
| RequestProcessor |
+--------------------+
| - process(request) |
+--------------------+
|
V
+-------------------+
| Controller |
+-------------------+
| - handle(request) |
+-------------------+
|
V
+------------------+
| Business |
+------------------+
| - doSomething() |
+------------------+
Code Example - Stateless Serving Function Pattern
This example is code representation of the above UML:
C++: Stateless.cpp.
C#: Stateless.cs.
Java: Stateless.java.
Python: Stateless.py.
Common Usage
The following are some common usages of the stateless serving function pattern:
Code Problem - Server Handler
In this example, a server application handles multiple types of requests using a stateless serving function design pattern. The Request class represents a request made to the server and provides a method to retrieve the request details. The Business class simulates processing the request by performing some business logic based on the request. In this example, it simply prints the request. The Controller class handles the request and delegates it to the Business class for processing. The RequestProcessor class maintains a mapping of endpoints to their respective controllers. It extracts the endpoint from the request and finds the corresponding controller to handle the request. The Application class serves as the entry point of the program. It allows registering controllers for specific endpoints and processes incoming requests.
In the main() function, we create an instance of the Application class and register two controllers for different endpoints.
We then create multiple requests and pass them to the serve() method of the application, which delegates the processing to the appropriate controller based on the request's endpoint.
When you run this program, you will see the requests being processed by the respective controllers based on their endpoints. If an invalid endpoint is provided, an error message will be displayed.
Request.h,
Business.h,
Controller.h,
RequestProcessor.h,
RequestProcessor.cpp,
Application.h,
Server.cpp.
Code Problem - Socket Based Server
Sample code for a simple socket-based server for handling requests is given below. This version uses Winsock for socket programming on Windows.
Note that you'll need to link against the Ws2_32.lib library.
MLModel.h,
StatelessServingFunction.h,
RequestHandler.h,
RequestHandler.cpp,
Server.h,
Server.cpp,
ServerMain.cpp.
The batch serving design pattern focuses on the efficient and reliable processing of large volumes of data in scheduled batches, rather than in real-time. This pattern is commonly used in data processing pipelines for tasks such as ETL (Extract, Transform, Load), data warehousing, and offline machine learning model training.
The Rationale
The Batch Serving Pattern is a resilience design pattern in machine learning systems that focuses on handling large volumes of inference requests efficiently by processing them in batches rather than individually. Instead of serving predictions one request at a time (as in online or real-time inference), batch serving collects many input records, runs inference over all of them at once, and writes the results to a persistent output store (e.g., a database, data lake, or file system). This pattern enhances resilience, scalability, and resource efficiency - it allows model serving systems to recover easily, reprocess failed batches, and operate reliably under heavy loads or limited computing resources.
The UML
Batch serving decouples the request-response model of real-time systems into a data-driven workflow:
The following is a very primitive diagram of the batch serving design pattern.
+-----------------------------------------------+
| Data Source |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Ingestion |
| - Collect data from various sources |
| - Store in centralized repository |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Job Scheduler (e.g., Airflow) |
| - Manage and orchestrate batch jobs |
| - Schedule jobs at regular intervals |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Batch Processing Framework |
| (e.g., Hadoop, Spark) |
| - Distribute data processing |
| - Ensure fault tolerance and scalability |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Transformation |
| - Clean, normalize, and aggregate data |
| - Apply business logic |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Output Storage |
| - Store processed data for consumption |
| - Use suitable data stores |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Monitoring and Logging |
| - Track job performance |
| - Log execution details and errors |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Fault Tolerance and Recovery |
| - Implement retry logic |
| - Use checkpointing |
| - Ensure idempotent operations |
+-----------------------------------------------+
Code Example - Batch Serving
Here is a simple example to demonstrate the batch serving design pattern. In this example,
we'll simulate a scenario where we process a batch of numbers by squaring each number in the batch.
C++: BatchServing.cpp.
C#: BatchServing.cs.
Java: BatchServing.java.
Python: BatchServing.py.
Common Usage
The batch serving design pattern is commonly used in various domains and applications where processing multiple requests or tasks in groups (batches) can significantly improve efficiency, reduce latency, and optimize resource utilization. Here are some common areas where this pattern is employed:
Code Problem - Batch Prediction
This example perform batch predictions using a linear regression model:
BatchPrediction.cpp.
data is defined as a constant vector of vectors of doubles. This represents our dataset directly in the code.
The LinearRegression class represents a simple linear regression model.
The model is initialized with a vector of coefficients and an intercept.
The predict() method makes a prediction for a single feature vector.
The batchPredict() method makes predictions for a batch of feature vectors.
For a discussion of machine learning applied to the very difficult problem of routing and placing digital electronic components on a micro-chip, see Route and Place.