Lecture recording here.
Lab recording here.
This week we study another resilience pattern: the continued model evaluation pattern. The continued model evaluation pattern can detect when a deployed model is no longer fit-for-purpose by continually monitoring model predictions and evaluating model performance. This is because model performance of deployed models degrades over time either due to data drift, concept drift or other changes to the pipelines which feed data to the model.
We will also look at the transform design pattern and the windowed inference design pattern. The transform reproducibility design pattern ensures that data transformations in processing systems can be consistently reproduced, providing data reliability, traceability, and ease of debugging. The windowed inference design pattern externalizes the model state and invoke the model from a stream analytics pipeline to ensure that features calculated in a dynamic, time-dependent way can be correctly repeated between training and serving.
| The Continued Model Evaluation Pattern | Machine Learning Design Patterns | Dr Ebin Deni Raj (Design Patterns for Resilient Serving- Continuous Model Evaluation 1:12:50-1:32:30) |
| Machine Learning Design Patterns (16:10-26:17) | |
| Pipeline Design Patterns | What are some common data pipeline design patterns? (Extract, Transform and Load) |
Assignment 5 - Multimodal Input: An Autonomous Driving System
Assignment 6 - Investigation of Design Patterns for Machine Learning
The Rationale
The rationale for the continued model evaluation pattern is to ensure that machine learning models perform effectively and reliably over time. Its role is to "keep checking if the model is still good." This pattern involves regularly evaluating and monitoring models after they have been deployed in a production environment. The goal is to assess model performance, detect potential issues or drift, and take appropriate actions to maintain or improve model accuracy and reliability.
The Continued Model Evaluation design pattern pattern runs in a continuous loop that
The UML
Here is the UML diagram for the continued model evaluation pattern:
+-------------------+
| ModelEvaluator |
+-------------------+
| - model: Model |
+-------------------+
| + evaluate(data) |
| + updateModel() |
+-------------------+
/\
|
|
|
|
|
+-------------------+
| Model |
+-------------------+
| - parameters |
+-------------------+
| + predict(data) |
+-------------------+
Code Example - Continued Evaluation Pattern
In the provided code, the Model class is implemented with a constructor to initialize model parameters and a predict()
method to perform the prediction.
The ModelEvaluator class holds an instance of the Model class and provides the evaluate() method to evaluate
data using the model. It returns the prediction result based on the model's prediction method. The updateModel() method
is used to update the model with new data or retrain the model.
In the main() function, you can create a ModelEvaluator object, load the data, evaluate the model
using the evaluate() method, and update the model using the updateModel() method.
Remember to replace Data with the appropriate data type used in your implementation and adjust the methods
and parameters according to your specific requirements.
C++: ContinuedEval.cpp.
C#: ContinuedEval.cs.
Java: ContinuedEval.java.
Python: ContinuedEval.py.
Common Usage
The following are some common usages of the continued model evaluation pattern:
Code Problem - Model Modification
In this example, we have a Data class that represents the input data, containing a vector of features. The Model class represents the model used for prediction, which consists of a vector of weights. The ModelEvaluator class is responsible for evaluating the model using the provided data and updating the model with new weights. In the main() function, we create a ModelEvaluator object with initial weights, load the input data, and evaluate the model using the evaluate() method. The prediction result is then printed to the console. Next, we update the model with new weights using the updateModel() method and evaluate the model again with the updated weights. The updated prediction result is printed to the console.
You can customize the example by modifying the number of features, adding additional evaluation logic, or
adjusting the model's prediction mechanism to suit your specific requirements.
Data.h,
Model.h,
Model.cpp,
ModelEvaluator.h,
ModelEvaluator.cpp,
ModelMod.cpp.
Code Problem - Linear Regression Model Modification
This example is similar to the previous. The below code creates a simple
linear regression model and continuously evaluates and updates it based on a stream of data.
Additionally, multithreading is used to simulate concurrent evaluation and updating.
LinearRegressionModel.h,
DataStreamGenerator.h,
ModelEvaluator.h,
ModelUpdater.h,
LinearRegressionModMain.cpp.
The transform design pattern for machine learning focuses on ensuring the reproducibility and consistency of data transformations, which are critical for training, testing, and deploying models. This pattern emphasizes deterministic transformations, version control, and environmental consistency to maintain data integrity and facilitate debugging.
This pattern "Turn your raw data into something the model can understand." Most real-world data is messy, inconsistent, or in the wrong format for an ML model. The Transform pattern describes how to clean, convert, and reshape data before feeding it into a model. This pattern ensures that data goes through a pipeline of transformations so that the final input is model-ready.
The Rationale
The problem is that the inputs to a machine learning model are not the features that the machine learning model uses in its computations. In a text classification model, for example, the inputs are the raw text documents and the features are the numerical embedding representations of this text. When we train a machine learning model, we train it with features that are extracted from the raw inputs. The solution is to explicitly capture the transformations applied to convert the model inputs into features.
The UML
The following is a very basic UML diagram of the transform design pattern.
+-----------------------------------------------+
| Raw Data Source |
| - Collect data from various sources |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Ingestion Layer |
| - Ingest and store raw data |
| - Ensure immutability |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Data Transformation Engine |
| - Apply transformations to data |
| - Ensure transformations are deterministic |
| - Version control for transformation logic |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Feature Store Layer |
| - Store transformed features |
| - Ensure features are versioned and immutable|
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Machine Learning Model Training |
| - Use versioned features for training |
| - Ensure reproducibility of training process |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Model Serving and Deployment |
| - Deploy trained models |
| - Use versioned features for prediction |
+-----------------------------------------------+
|
v
+-----------------------------------------------+
| Monitoring and Feedback Loop |
| - Monitor model performance |
| - Collect feedback for continuous improvement|
+-----------------------------------------------+
Raw Data Source: Collects data from various sources.Code Example - Transform
Below is a simple example of using the transform design pattern for a machine learning workflow. This example
demonstrates data normalization, which is a common transformation step. We'll use a basic class to handle the
normalization of a dataset.
C++: Transform.cpp.
C#: Transform.cs.
Java: Normalizer.java,
Transform.java.
Python: Transform.py.
Common Usage
The transform design pattern is widely used in machine learning for various purposes. Here are some common usages:
Code Problem - Data Normalization
The following code uses the transform design pattern for data normalization. The loadData function simulates the
loading of numerical data:
MultiTransform.cpp.
The Normalizer class performs data normalization.
The fit() method calculates the means and standard deviations of the features.
The transform() method normalizes a single feature vector using the stored means and standard deviations.
The fitTransform() method fits the normalizer to the data and then transforms it.
The Rationale
The Windowed Inference Pattern is used when the model should not process an entire long sequence at once, but instead breaks the input into fixed-size overlapping or non-overlapping "windows" and runs inference on each window separately. This pattern is especially important for time series, sensor streams, log data, and long text/audio sequences.
"Don't look at all the data at once - look at it in chunks (windows)." Sometimes the data coming into a model is too big, continuous, or arrives in a stream. You cannot process all of it at once. So instead of feeding the entire dataset to the model, you break the data into smaller windows, process each window, and then combine the results.
The Windowed Inference Pattern exists because many ML models cannot process arbitrarily long sequences at once, or because doing so would be computationally expensive, slow, and unnecessary. By splitting the input into fixed-size windows and running inference on each slice, the pattern enables real-time predictions, reduces latency, handles memory limits, preserves temporal relevance, lowers compute costs, and simplifies both training and deployment - especially for streaming, time-series, and log-analysis tasks.
The UML
Below is a simplified UML diagram for the Windowed Inference design pattern:
Horizontal bar - "Input sequence / time series". UML equivalent: this is the DataStream or InputSequence object.
It represents a long ordered list of data points, such as timestamps, log entries, sensor readings, or tokens.
Rectangles labeled "Window 1", "Window 2", "Window 3". UML equivalent: each rectangle is an instance of a Window class, representing a slice of the input sequence.
These windows are created by a WindowGenerator or WindowManager component, which takes the long InputSequence, and produces many Window objects (either overlapping or non-overlapping)
Conceptually, each Window is then passed to a Model component, which produces a prediction for that window. The predictions may optionally be sent to an Aggregator that combines the window-level outputs into a final result (for example: maximum, mean, majority vote, or "any window anomalous?").
Below is a more complete UML diagram for the Windowed Inference design pattern:
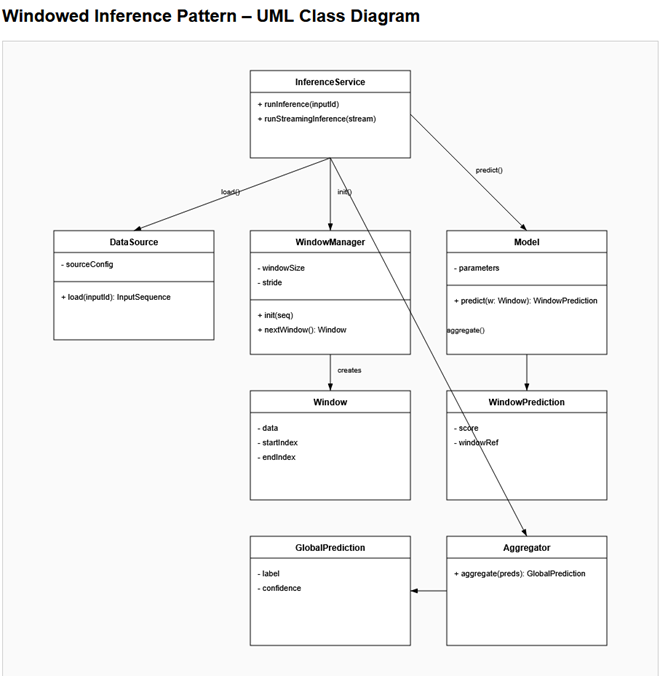
The components are described below:
DataSource.
Provides the raw input sequence that will be processed (for example, a list of data points).
It passes this sequence to the WindowManager.
WindowManager.
Takes the full input sequence and splits it into smaller pieces called Windows
(for example, chunks of fixed length). It creates and hands out Window objects one by one.
Window.
Represents one slice of the original sequence. It stores the data for that slice
and the indices (start and end positions) inside the full sequence.
This corresponds to "Window 1", "Window 2", "Window 3" in the diagram.
Model.
Takes a single Window as input and produces a prediction for that window
(for example, a score or classification).
WindowPrediction.
Stores the result of the model's prediction for one Window
(for example, a score) and may keep a reference back to that Window.
Aggregator.
Combines many WindowPrediction objects into a single overall result
(for example, by taking the maximum or average).
InferenceService (or API).
Coordinates the whole process: it gets data from DataSource, asks WindowManager
for Windows, calls the Model on each Window, sends all WindowPredictions to the
Aggregator, and returns the final result to the caller.
Code Example - Windowed Inference
Below is a simple example of using the windowed inference design pattern for machine learning
that reflects the idea of splitting sequence into segments, predictions per segment, and aggregation
at the end.
C++: WindowedInference.cpp.
C#: WindowedInference.cs.
Java: WindowedInference.java,
Python: WindowedInference.py.
Common Usage
Code Problem - Segmented Prediction
Below is an example that performs segmented prediction using the Windowed Inference pattern.
It does not perform real machine learning - it only simulates the flow, demonstrating how windows
flow through the pipeline
(DataSource → WindowManager → Model → Aggregator → InferenceService):
DataSource.h, Input provider,
Window.h, Data slice,
WindowManager.h, Window creator,
WindowPrediction.h, Segment result,
Model.h, Predictor,
Aggregator.h, Result combiner,
InferenceService.h, Pipeline controller
SegmentedPred.cpp, Main program.
The below provides scenarios which can be resolved by one (or more) of the machine learning design patterns that we have covered so far. Read the scenario, choose a pattern, and explain your pattern of choice.
Question: Which ML design pattern should be applied to most effectively address the extreme class imbalance?
Correct Answer.
Question: Which ML design pattern ensures that each prediction request is fully independent and safely scalable?
Correct Answer.
Question: Which ML design pattern supports chunking the stream into overlapping windows and performing segmented inference?
Correct Answer.
Question: Which ML design pattern allows them to leverage an existing pretrained model to improve performance on their smaller dataset?
Correct Answer.