Lecture recording here.
Lab recording here.
This week we will look at three patterns that modify model training: checkpoints, transfer learning and distribution strategy. The checkpoints pattern stores the full state of the model periodically, so that partially trained models are available and can be used to resume training from an intermediate point, instead of starting from scratch. The transfer learning pattern The transfer learning pattern takes parts of a previously trained model, freezes the weights, and uses these nontrainable layers in a new model that solves a similar problem. This is needed when there is a lack of large datasets that are needed to train complex machine learning models. The distribution strategy pattern carries the training loop out at scale over multiple workers, taking advantage of caching, hardware acceleration, and parallelization.
Assignment 4 - Multi-View Machine Learning Predictor
Assignment 5 - Multimodal Input: An Autonomous Driving System
The Rationale
The Checkpoints design pattern in machine learning ensures that progress during long or iterative training processes is safely preserved and recoverable. It involves periodically saving the model's state, parameters, and relevant metadata so training can resume from the most recent or best-performing point instead of restarting from scratch after interruptions or failures. This approach improves fault tolerance, enables reproducibility, supports early stopping and model selection, and saves computation time—making it an essential pattern for maintaining reliability and efficiency in real-world ML pipelines.
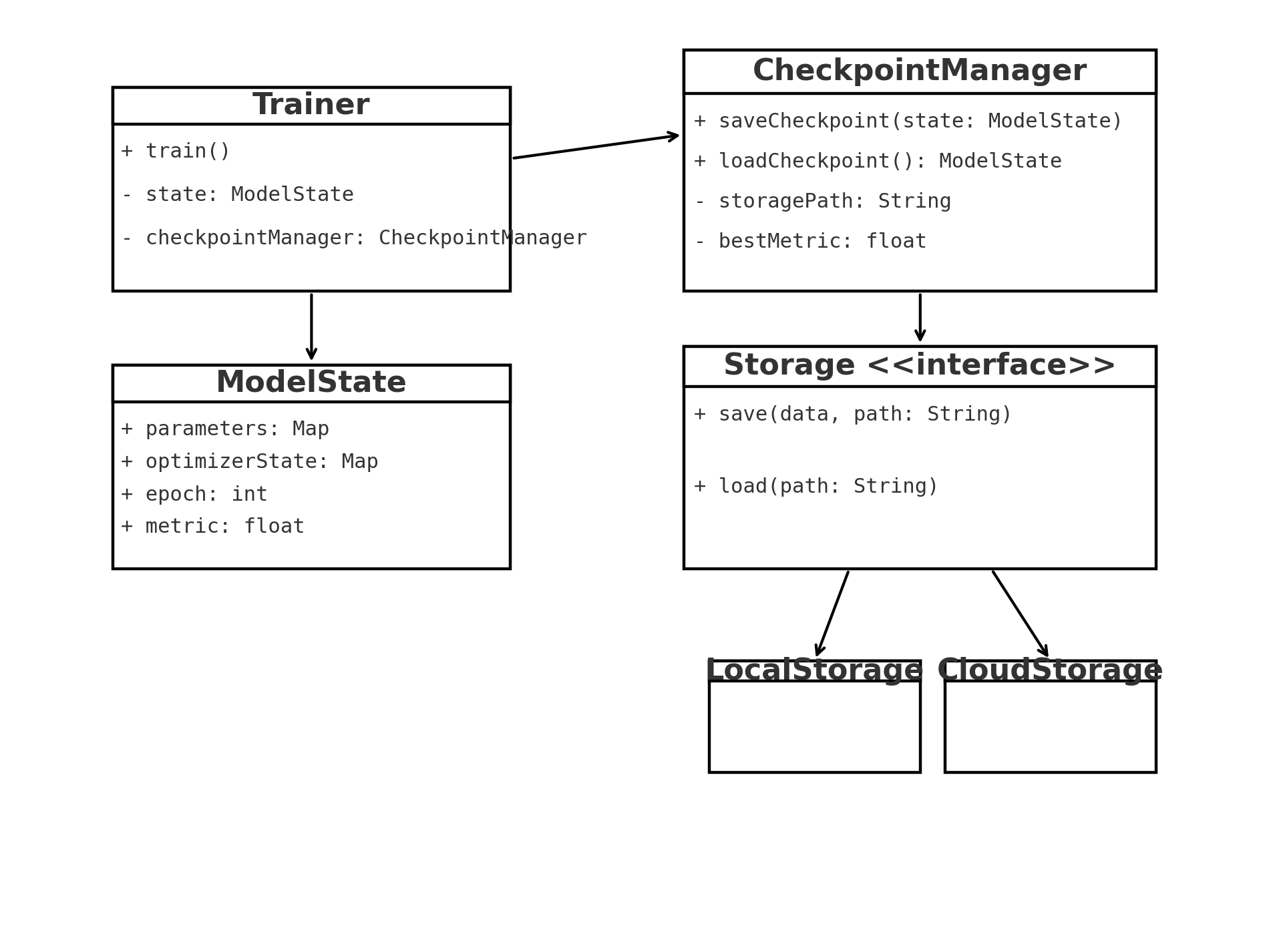
The UML
Code Example - Checkpoints
The sample code demonstrates the Checkpoints design pattern, which allows a long-running process (like model training)
to save and resume progress safely. It defines a ModelState class to hold the model's state (epoch and performance metric), a
Storage interface for saving and loading data, and a LocalStorage class that implements this interface using simple file I/O.
The CheckpointManager tracks the best metric achieved so far and saves a checkpoint only when performance improves, while the
Trainer class simulates a training loop that updates the model state and delegates checkpointing duties to the manager. Together,
these components show how checkpointing separates progress persistence from training logic, improving reliability and fault
tolerance in long-running computations.
C++: Checkpoints.cpp,
C#: Checkpoints.cs,
Java: Checkpoints.java,
Python: Checkpoints.py.
Common Usage
the Checkpoints design pattern is a foundational reliability and recovery mechanism across many domains, especially in large-scale computation, machine learning, and data processing. Here are five real-world examples of where it's used in industry:
In short, the Checkpoints pattern is widely used anywhere reliability, fault recovery, or reproducibility are critical — from deep learning and big data to real-time analytics, scientific computing, and distributed storage systems.
Code Problem - Logistic Regression
This C++ program demonstrates an in-memory Checkpoints design pattern applied to logistic regression training. It builds a
small machine learning model that performs gradient descent on synthetic data while automatically saving and restoring
checkpoints entirely in memory (no files). A CheckpointManager tracks the latest and best model states, managed by an
InMemoryStorage class that acts like a volatile database. When the loss diverges (spikes or becomes NaN/∞), the system
rolls back to the last best checkpoint, reduces the learning rate, and continues training — ensuring resilience and
stability. This example illustrates how checkpointing improves fault tolerance, adaptive learning rate control, and
recovery in iterative optimization without relying on external storage.
ModelState.h, the model state structure,
Storage.h, storage interface class,
InMemoryStorage.h, concrete storage,
CheckpointPolicy.h, the checkpoint policy structure,
CheckpointManager.h, the checkpoint manager,
Dataset.h, the dataset structure (complex),
Trainer.h, the trainter structure (complex),
Utilities.h,
Utilities.cpp, some mathematical utilities
LRegress.cpp, the main function.
Memento vs. ML Checkpoints
| Aspect | Memento | ML Checkpoints |
|---|---|---|
| Primary goal | Undo/redo; safe state rollback for a single object | Fault tolerance, resumability, and reproducibility of training |
| Scope of state | Typically one object's internal fields | Full training pipeline: model weights, optimizer state, schedulers, RNG seeds, epoch/step, data-loader cursors |
| Lifetime | Short-lived, in-memory, often per user action | Long-lived, on disk/cloud; may be versioned and shared |
| Encapsulation | Caretaker can't access internals (black-box snapshot) | Not about encapsulation; artifacts are intentionally inspectable/portable |
| Granularity | Fine (per action) | Coarse/batched (e.g., every N steps/epochs or on metric plateaus) |
| Performance concerns | Minimal (object copy) | Heavy I/O and size; trade-offs around frequency, format, compression |
| Concurrency/distribution | Usually single-process | Commonly multi-GPU/multi-node; must be atomic and consistent across workers |
| Failure model | Logical errors/UX (revert recent change) | System faults/preemption; recover from crashes or move training between hosts |
| Tooling | Pure OO pattern | Framework support (e.g., PyTorch state_dict, TF Checkpoint, orchestration hooks) |
Transfer learning, used in machine learning, is the reuse of a pre-trained model on a new problem. In transfer learning, a machine exploits the knowledge gained from a previous task to improve generalization about another. For example, in training a classifier to predict whether an image contains food, you could use the knowledge it gained during training to recognize drinks. For more information see What Is Transfer Learning?.
The Rationale
The rationale behind the transfer learning design pattern stems from the observation that deep learning models trained on large-scale datasets can learn generic features that are useful for a wide range of tasks. Transfer learning leverages this idea by reusing pre-trained models as a starting point for new tasks.
The UML
Here is the UML diagram for the transfer learning pattern:
+---------------------------------+
| Pre-trained Model |
+---------------------------------+
| |
| - Trained on large-scale dataset|
| - Captures generic features |
+---------------------------------+
^
|
+---------------------------------+
| New Task-Specific Model |
+---------------------------------+
| |
| - Reuses pre-trained model |
| - Freezes pre-trained layers |
| - Adds new task-specific layers |
| - Fine-tunes the model |
+---------------------------------+
Code Example - Transfer Learning
In this code, we have two classes: PretrainedModel and NewTaskModel. The PretrainedModel class represents the pre-trained model, and it has methods to load the pre-trained model weights and extract features using the pre-trained layers. The NewTaskModel class represents the model for the new task. It has methods to add new task-specific layers and perform fine-tuning on the new task-specific data. In the main() function, we create an instance of PretrainedModel and load the pre-trained model weights. Then, we create an instance of NewTaskModel. The transfer learning process involves extracting features from the pre-trained model using pretrainedModel.extractFeatures(), adding task-specific layers using newTaskModel.addTaskSpecificLayers(), and fine-tuning the model on the new task-specific data using newTaskModel.fineTune(). Finally, you can use the trained new task-specific model for inference or any other desired tasks.
Note that this code is a basic representation to illustrate the concept of transfer learning in C++. In practice,
you would need to adapt it to the specific deep learning framework or library you are using and incorporate additional
functionalities as needed:
C++: TransferLearning.cpp.
C#: TransferLearning.cs.
Java: TransferLearning.java.
Python: TransferLearning.py.
Common Usage
The transfer learning design pattern is commonly used in various scenarios to leverage the knowledge gained from pre-trained models and apply it to new tasks or domains. The following are some common usages of the transfer learning design pattern:
Code Problem - Sentiment Analysis
In this example, we have a PretrainedWordEmbeddings class that represents pre-trained word embeddings. It has
methods to load the pre-trained embeddings from a file and retrieve the word embeddings for specific words.
The SentimentAnalysisModel class represents the sentiment analysis model. It has a dependency on the
PretrainedWordEmbeddings class. The model loads the pre-trained word embeddings and uses them for training
and prediction.
In the main() function, we create an instance of SentimentAnalysisModel, load the pre-trained word
embeddings, and train the model using transfer learning by calling trainModel() with the training data file path.
Finally, we use the trained model for sentiment prediction by calling predictSentiment() with an input text.
The predicted sentiment class is returned and printed to the console.
PretrainedWordEmbeddings.h,
SentimentAnalysisModel.h,
SentimentAnalysisModel.cpp,
Sentiment.cpp.
Code Problem - Image Classification
In the following example, a pre-trained model is used to help with image classification.
PretrainedModel.h,
TaskSpecificModel.h,
ImageClassificationModel.h,
ImageClassificationMain.cpp.
As the size of the neural networks increases, so does their requirement of computation and memory demands. The longer it takes to train the model, the more resources are expended. To address these challenges, a sophisticated distribution strategy is employed, optimizing the training process across multiple workers, typically GPUs. This distribution strategy enables efficient parallelization of the training process, allowing for the handling of larger models and dataset while minimizing the training time.
The Rationale
The rational in distributed training design pattern is rooted in efficiency and scalability. By partitioning data into batches and distributing workload across multiple GPUs or machines, this approach significantly reduces training time, allows for the handling of models that exceed single-GPU memory capacity, and enables efficient processing of massive datasets. This strategy not only maximizes hardware resource utilization but also scales effectively as model complexity and data volume increase, ultimately facilitating the development of more sophisticated deep learning models that can tackle increasingly complex problems.
The UML
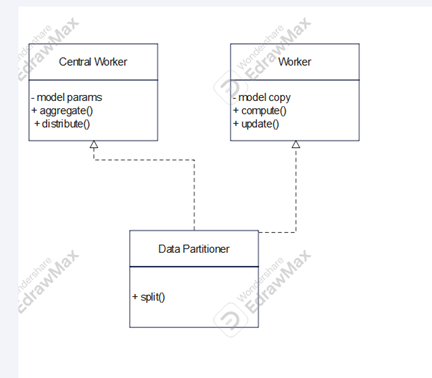
Components:
Code Example - Distribution Strategy
This sample program is a simple skeleton illustrating the Machine Learning Distribution Strategy design pattern. It simulates a distributed training setup with three key components:
Common Usage
The Distribution Strategy pattern finds widespread application across various sectors of the software industry:
Code Problem - Distributed Training Concept Simulator
This C++ program is a simple multithreaded demonstration of the Distribution Strategy design pattern used in distributed machine
learning systems. It conceptually shows how a CentralServer coordinates with multiple Workers to perform parallel tasks
without involving any mathematical computations. The DataPartitioner divides a total workload (e.g., data batches) among workers,
the CentralServer broadcasts a model version to all workers, and each Worker runs in its own thread, "processing" its assigned batches
by sleeping briefly to simulate work before sending a completion signal back to the server. The server collects these acknowledgements,
aggregates them, and increments the model version for the next round—illustrating the key steps of distribute, parallel process,
aggregate, and update.
Worker.h,
DataPartitioner.h,
CentralServer.h,
DistTraining.cpp.
What it demonstrates:
Distribution Strategy vs Parallel Processing
| Concept | Description |
|---|---|
| Parallel Processing | Breaks a task into smaller independent pieces and runs them simultaneously for speed. Each process works independently and may not share learned state. |
| Distribution Strategy Pattern | Coordinates model training across multiple devices or machines so that parameters are synchronized and convergence is consistent. |
| Aspect | Parallel Processing | Distribution Strategy Pattern |
|---|---|---|
| Goal | Faster computation by running tasks concurrently | Scalable and fault-tolerant model training across devices |
| Context | Generic computing or data processing | Machine learning systems (e.g., TensorFlow, PyTorch) |
| Shared State | Usually none | Workers share gradients, parameters, and updates |
| Coordination | Minimal or none | Central orchestration via parameter servers or all-reduce |
| Aspect | Parallel Processing | Distribution Strategy Pattern |
|---|---|---|
| Data Flow | Independent inputs → independent outputs | Shared global model updated collectively |
| Synchronization | Optional (join at end) | Essential — frequent gradient aggregation and synchronization |
| Communication Cost | Low (simple message passing) | High — large tensors exchanged between nodes |
Parallel processing = many chefs cooking different dishes independently.
Distribution strategy = many chefs cooking parts of the same dish, constantly sharing ingredients and results.
| Feature | Parallel Processing | Distribution Strategy |
|---|---|---|
| Purpose | Speed up independent tasks | Coordinate shared model training |
| Coordination | Low | High |
| Shared State | None | Shared model parameters |
| Communication | Minimal | Frequent and structured |
| Failure Recovery | Task-level retry | Requires checkpointing and synchronization |
| Frameworks | OpenMP, multiprocessing, MapReduce | TensorFlow tf.distribute, PyTorch DistributedDataParallel, Horovod |