Lecture recording here.
This week we start design patterns for machine learning. We will look at one data representation pattern - the embeddings pattern. We will also look at one problem representation pattern - the rebalancing pattern. The embeddings pattern is for high-cardinality features where closeness relationships are important to preserve. It learns a data representation that maps high-cardinality data into a lower-dimensional space in such a way that the information relevant to the learning problem is preserved. The rebalancing pattern uses downsampling, upsampling, or a weighted loss function for heavily imbalanced data.
| Machine Learning, Supervised Learning: | #4 Machine Learning Specialization |
| #5 Machine Learning Specialization. | |
| Machine Learning, Unsupervised Learning: | #6 Machine Learning Specialization |
| #7 Machine Learning Specialization. | |
| Machine Learning Design Patterns: | ML Design Patterns by Lak (1 hour lecture) |
| Machine Learning Design Patterns (1 hour 20 minute lecture) | |
| The Embeddings Pattern | Machine Learning Design Patterns Embeddings (7:05-12:40) |
| Machine Learning Design Patterns | Dr Ebin Deni Raj Embeddings (43:42-59:35) | |
| The Rebalancing Pattern | Machine Learning Design Patterns | Dr Ebin Deni Raj Rebalancing (59:30-1:12:50) |
| Machine Learning Design Patterns | Michael Munn, Google (14:10-) |
These patterns are about how we prepare and organize data so a machine can understand it. They make sure the data is in the right form - clean, structured, and meaningful - before training a model.
Example: Using Embeddings to turn words into numbers that capture their meaning.
These patterns deal with how we define the problem for the model to solve. They help us choose the best way to express the question - classification, regression, ranking, etc. - so the model can learn effectively.
Example: Turning "recommend a movie" into a ranking problem instead of a yes/no question.
These patterns focus on how we train the model - improving accuracy, speed, and generalization. They might change how the model learns from data or how we combine multiple models.
Example: Using Ensemble Learning (combining several models) to get better results.
These patterns help make ML systems strong and reliable in the real world. They handle unexpected inputs, missing data, or system failures, so the model doesn't break easily.
Example: Using Checkpoints to save progress during training, so it can restart if something fails.
These patterns ensure that we can repeat the same experiment and get the same results. They standardize how data, models, and code are tracked and shared.
Example: Keeping exact versions of data and model configurations so results can be verified later.
These patterns focus on doing AI the right way - fairly, safely, and ethically. They make sure models are transparent, unbiased, and respect privacy.
Example: Using a Fairness Lens pattern to detect and reduce bias in predictions.
| Category | Simple Meaning | Example |
|---|---|---|
| Data Representation | Getting data ready for ML | Embeddings |
| Problem Representation | Defining the problem clearly | Ranking, classification |
| Modify Model Training | Improving how models learn | Ensembles |
| Resilience | Making systems reliable | Checkpoints |
| Reproducibility | Ensuring results can be repeated | Version tracking |
| Responsible AI | Building fair, ethical systems | Fairness Lens |
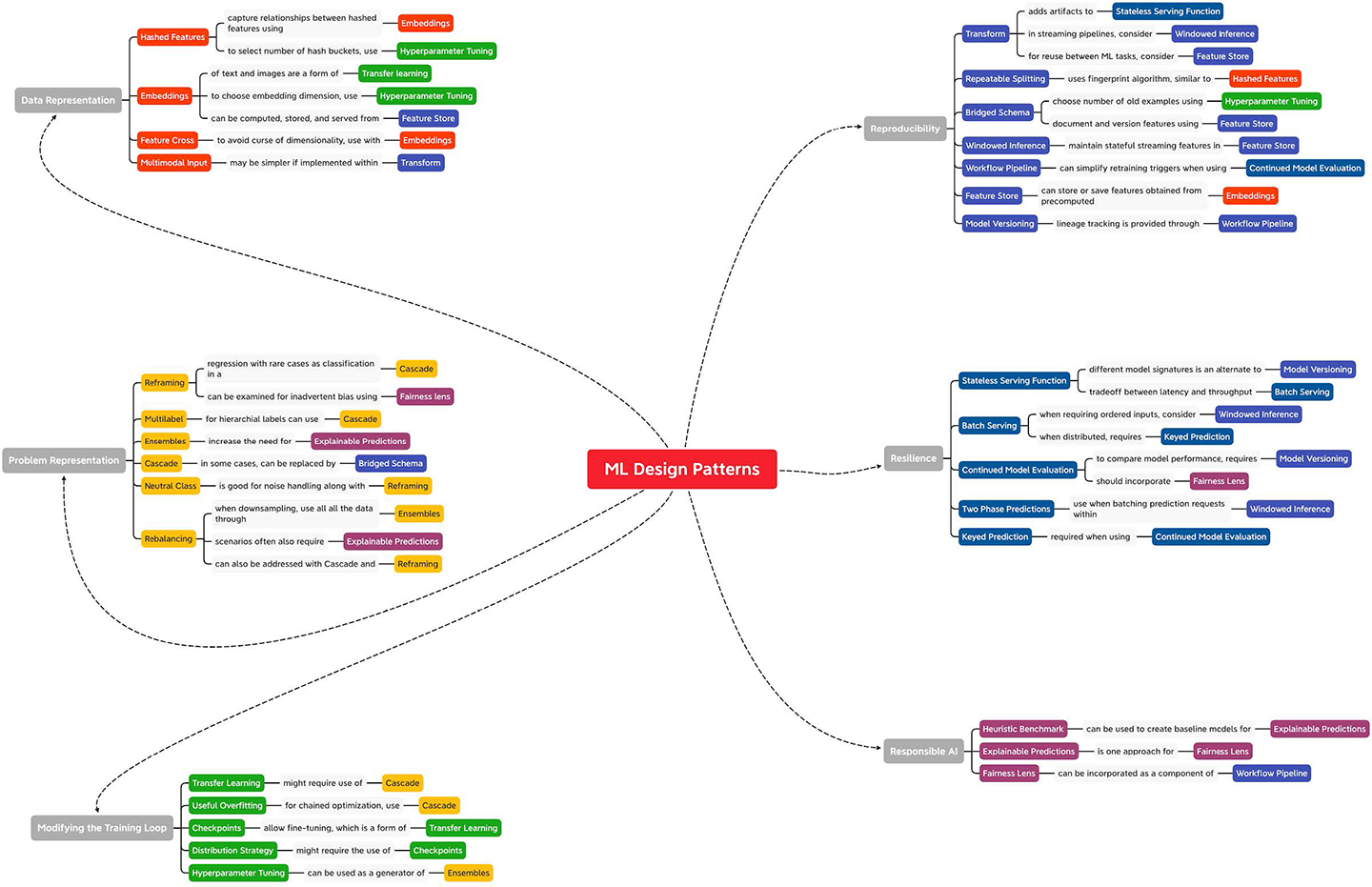
These are summarized in the image:
These are also summarized in the second half of Common Patterns.docx. The bolded patterns are the patterns we will cover in class. The number in brackets shows the popularity rank of a particular pattern. The patterns in red were covered last year but due to declining popularity will not be covered in this year's class. The patterns in green will be covered for the first time this year due to increasing popularity. Note that we cover the 16 most popular machine learning design patterns.
There is growing pressure for fairness, transparency, interpretability, privacy, and ethical AI use. Organizations must meet internal governance and external regulations such as GDPR and the EU AI Act.
Implication: Patterns like "fairness lens", "explainable predictions", and "heuristic benchmark" are gaining attention.
As ML systems move from research to production (MLOps), robustness, monitoring, drift detection, and reliability have become critical. Systems must operate reliably at scale in changing environments.
Implication: Patterns such as "continued model evaluation", "stateless serving function", and "two-phase predictions" are becoming more common.
With complex models and collaborative teams, it's vital to reproduce experiments and results. This is also important for audits and compliance.
Implication: Patterns like "workflow pipeline", "model versioning", and "feature store" are increasingly standard in production systems.
Foundational techniques such as embeddings, feature crosses, and hashing are well established. The focus is shifting from creating representations to managing operational and ethical challenges.
Problem formulation patterns (classification, regression, ranking) are mature and standardized. There is less emphasis on new approaches in this area compared to production and governance patterns.
While still useful (transfer learning, hyperparameter tuning, distributed training), most of these are handled by existing frameworks. Focus is moving toward deployment and lifecycle management.
| Category | Trend | Key Reasons |
|---|---|---|
| Data Representation | Plateauing | Foundational techniques are mature |
| Problem Representation | Plateauing | Standard formulations widely known |
| Modify Model Training | Stable | Frameworks automate common techniques |
| Resilience | Increasing | Focus on reliability, drift detection, and MLOps |
| Reproducibility | Increasing | Auditability and versioning demands |
| Responsible AI | Increasing | Ethical and regulatory requirements |
For a full course on machine learning, see the playlist Stanford CS229: Machine Learning Full Course taught by Andrew Ng, Autumn 2018. Of interest to our study of machine learning design patterns is the second lecture on linear regression and gradient descent. See Stanford CS229: Machine Learning - Linear Regression and Gradient Descent.
For a shorter course on machine learning, see the playlist Machine Learning Specialization by Andrew Ng. For shorter videos on training data, see the following videos on supervised learning: #4 Machine Learning Specialization and #5 Machine Learning Specialization. See also the following videos on unsupervised learning: #6 Machine Learning Specialization and #7 Machine Learning Specialization.
The Rationale
The rationale for the embeddings design pattern in machine learning is to represent high-dimensional categorical or discrete features in a lower-dimensional continuous vector space. Embeddings are learned representations that capture meaningful relationships and semantic information between different categories or entities present in the data.
The embeddings pattern translates many categories (words, users, products) into small, meaningful numeric vectors that a model can use to make predictions. There are two main parts:
The UML
Here is a very rough UML diagram for the embeddings pattern:
+------------------+ +------------------+ | EmbeddingLayer |<>--------------| Model | +------------------+ +------------------+ | - inputDim: int | | - embeddingLayer: EmbeddingLayer | - embeddingDim: int | | +------------------+ +------------------+ | + getEmbedding() | | + predict() | +------------------+ +------------------+
1) Embedding Layer (the translator)
[0.2, -0.7, 0.5, ...].
2) Model (the learner)
It may also contain the following components:
3) Training Data Class: The training data class holds the data the model learns from, including input categories and the correct answers (targets) used to train and adjust the embeddings. It may contain the input categorical features, target variables, and other relevant data for training the embeddings. It serves as the input to the model during the training phase.
4) Inference Data Class: The inference data class holds new input data used after training so the model can generate embeddings and make predictions. It may contain the categorical features for which embeddings are generated, as well as any additional input data required for prediction.
Code Example - Embeddings Data Pattern
The following is a simple example of the embeddings data pattern:
C++: Embedding.cpp.
C#: Embeddings.cs.
Java: Embeddings.java.
Python: Embeddings.py.
Common Usage
The following are some common usages of the embeddings pattern:
Code Problem - Movie Recommendations
We want to implement a system that recommends movies to a user based on a list of
watched movies. We need an EmbeddingLayer class responsible for generating and
retrieving embeddings. We need a Movie class to represent a movie with an ID and
a title. We need a RecommenderSystem class that calls a recommendMovie
function for a specific user, passing their ID and the list of movies they've already
watched. The recommendMovie function takes a user ID and a list of watched movies
and recommends a movie based on a users embeddings and similarity metric. The code is seen
below.
Movie.h,
EmbeddingLayer.h,
RecommenderSystem.h,
MovieMain.cpp.
Code Problem - Predicting Financial Data
The following program uses historical prices as well as weights to predict a stock price for a given day.
The result is a dot product of the two vectors (historical prices, weights).
VectorOperations.h, vector dot product
FinancialData.h,
StockPredictionModel.h, contains the embedded data
FinancialDataMain.cpp.
The Rationale
The rebalancing machine learning design pattern, also known as class rebalancing or data rebalancing, is employed in machine learning to address class imbalance issues in datasets. Class imbalance refers to a situation where the number of samples in different classes of a classification problem is significantly imbalanced, with one class having a much larger number of instances than the others.
The UML Diagram
Here is a simple UML diagram for the rebalancing design pattern:
_______________ ________________
| Dataset |<>------------>| Rebalancer |
|______________| |________________|
| - data | | - rebalance() |
| - labels | | - get_data() |
| - num_classes| | - get_labels() |
|______________| |________________|
^
|
|
_____________________
| BaseModel |
|___________________|
| - train() |
| - predict() |
| - evaluate() |
|___________________|
^
|
|
_____________________
| RebalancedModel |
|___________________|
| - rebalancer |
| - train() |
| - predict() |
| - evaluate() |
|___________________|
Code Example - Rebalancing design pattern
The following is a simple code example of the rebalancing design pattern:
C++: Rebalancing.cpp.
C#: Rebalancing.cs.
Java: Rebalancing.java.
Python: Rebalancing.py.
Common Usage
The rebalancing design pattern is commonly used in various domains within the software industry where dealing with imbalanced datasets is a challenge. The following are some common usages of the rebalancing design pattern:
Code Problem - SMOTE rebalancer (simple)
The rebalancing design pattern in machine learning involves adjusting the class distribution in the training data to handle imbalanced datasets. Here's an example in C++ that demonstrates the rebalancing design pattern using the Synthetic Minority Over-sampling Technique SMOTE to handle imbalanced data. In a real - world scenario, you would need to integrate a more sophisticated SMOTE algorithm or other methods to effectively rebalance the data before training your machine learning models.
The code is seen below:
DataSample.h,
Rebalancer.h,
RebalanceMain.cpp.
Code Problem - SMOTE algorithm
The following code contains pseudocode for the SMOTE algorithm:
Sample.h,
Smote.h,
SmoteMain.cpp.
Code Problem - SMOTE rebalancer (complex)
As above, the Rebalancer class uses the SMOTE algorithm to generate synthetic samples for the minority classes in the dataset. The rebalanced dataset is then used to train the base model (DecisionTreeModel) using the RebalancedModel class. The rebalanced model can then be used for predictions.
The code is seen below:
Dataset.h,
Rebalancer.h,
Rebalancer.cpp,
BaseModel.h,
DecisionTreeModel.h,
RebalancedModel.h,
RebalPredictor.cpp.