Week 4 - Black Box Testing
Lecture recording (Jan 30, 2025)
here.
Lab recording (Jan 31, 2025)
here.
Introduction
Black box testing involves looking at the specifications and does not require examining the code of a program.
Black box testing is done from the customer's viewpoint. The test engineer engaged in black box testing only
knows the set of inputs and expected outputs and is unaware of how those inputs are transformed into outputs by the software.
Black box testing is done without the knowledge of the internals of the system under test.
Videos
Assignment(s)
Assignment 1 - Artificial Intelligence in Software Testing
Assignment 2 - White Box Testing
Lecture Material
Why Black Box Testing
The tester may or may not know the technology or the internal logic of the product. However, knowing the technology
and the system internals helps in constructing test cases specific to the error-prone areas. Test scenarios can be
generated as soon as the specifications are ready. Since requirements specifications are the major inputs for black
box testing, test design can be started early in the cycle.
Black box testing is done based on requirements It helps in identifying any incomplete, inconsistent
requirement as well as any issues involved when the system is tested as a complete entity.
Black box testing addresses the stated requirements as well as implied requirements Not all the requirements
are stated explicitly, but are deemed implicit. For example, inclusion of dates, page header, and footer may not be
explicitly stated in the report generation requirements specification. However, these would need to be included while
providing the product to the customer to enable better readability and usability.
Black box testing encompasses the end user perspectives Since we want to test the behavior of a product from
an external perspective, end-user perspectives are an integral part of black box testing.
Black box testing handles valid and invalid inputs It is natural for users to make errors while using a product.
Hence, it is not sufficient for black box testing to simply handle valid inputs. Testing from the end-user perspective
includes testing for these error or invalid conditions. This ensures that the product behaves as expected in a valid
situation and does not hang or crash when provided with an invalid input. These are called positive and negative test
cases.
Requirements Based Testing
Requirements testing deals with validating the requirements given in the Software Requirements Specification (SRS)
of the software system. Not all requirements are explicitly stated; some of the requirements are implied or implicit.
Explicit requirements are stated and documented as part of the requirements specification. Implied or implicit
requirements are those that are not documented but assumed to be incorporated in the system.
The precondition for requirements testing is a detailed review of the requirements specification.
Requirements review ensures that they are consistent, correct, complete, and testable. This process ensures that
some implied requirements are converted and documented as explicit requirements, thereby bringing better clarity
to requirements and making requirements based testing more effective.
Requirements are tracked by a Requirements Traceability Matrix (RTM). An RTM traces all the requirements from their
genesis through design, development, and testing. This matrix evolves through the life cycle of the project. To start
with, each requirement is given a unique id along with a brief description. The requirement identifier and description
can be taken from the Requirements Specification (below table) or any other available document that lists the requirements
to be tested for the product. In systems that are more complex, an identifier representing a module and a running serial
number within the module (for example, INV-01, AP-02, and so on) can identify a requirement.
Each requirement is assigned a requirement priority, classified as high, medium or low. This not only enables prioritizing
the resources for development of features but is also used to sequence and run tests. Tests for higher priority requirements
will get precedence over tests for lower priority requirements. This ensures that the functionality that has the highest risk
is tested earlier in the cycle. Defects reported by such testing can then be fixed as early as possible.
As we move further down in the life cycle of the product, and testing phases, the cross-reference between requirements and the
subsequent phases is recorded in the RTM. In the example given here, we only list the mapping between requirements and testing;
in a more complete RTM, there will be columns to reflect the mapping of requirements to design and code.
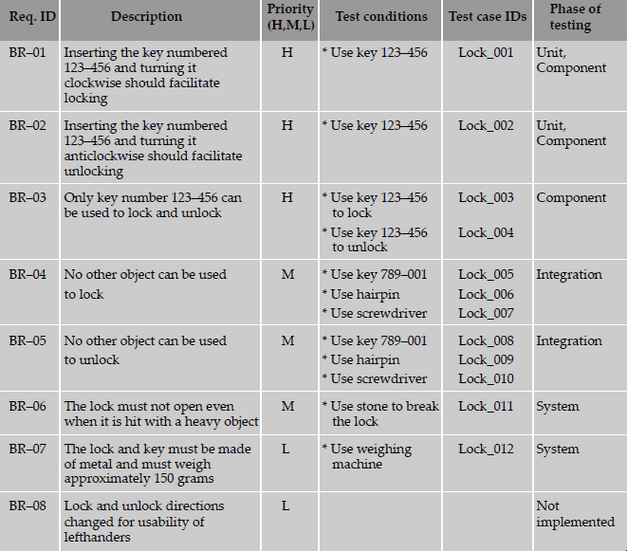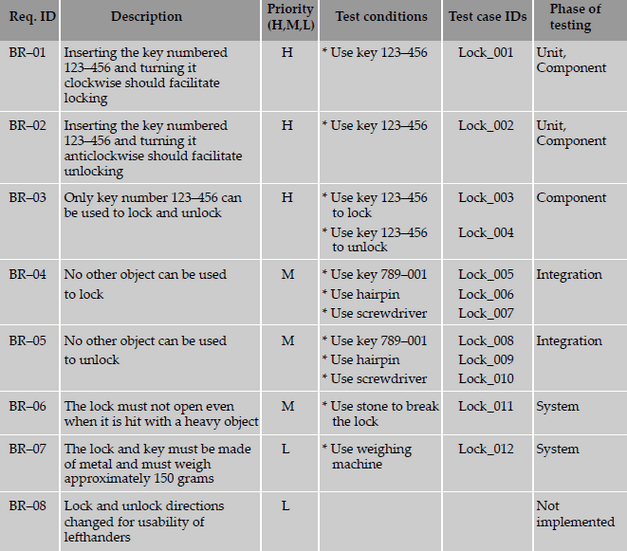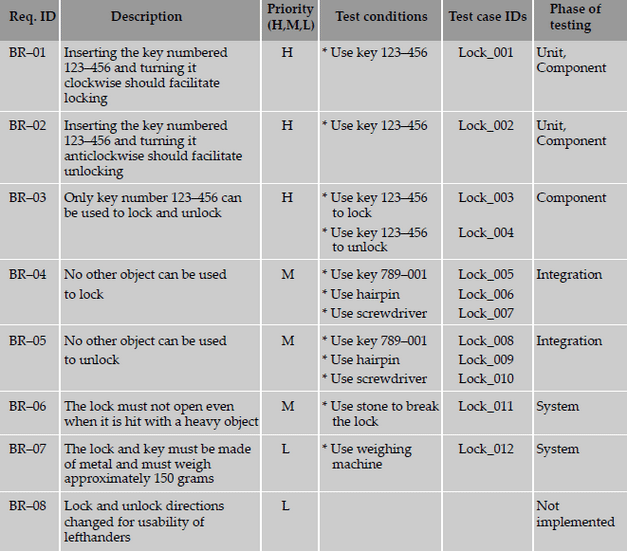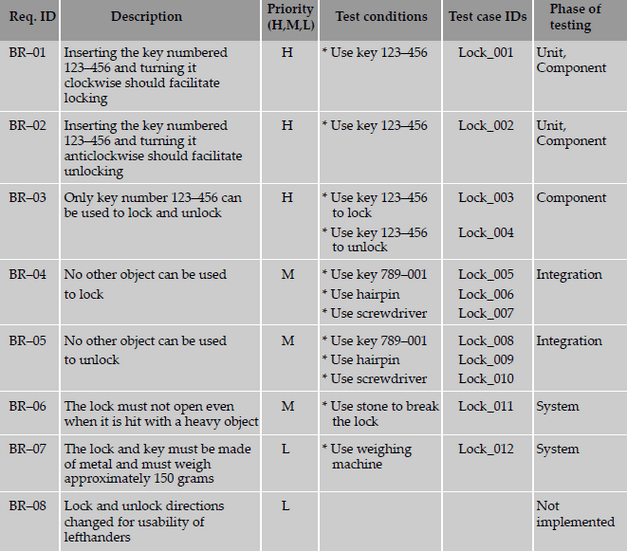
The following are sample requirements specification for a lock and key system.

The test conditions column lists the different ways of testing the requirement. Identification of all the test conditions
gives a comfort feeling that we have not missed any scenario that could produce a defect in the end-user environment.
These conditions can be grouped together to form a single test case. Alternatively, each test condition can be mapped
to one test case.
The test case IDs column can be used to complete the mapping between test cases and the requirement. Test case
IDs should follow naming conventions so as to enhance their usability. In a more complex product made up of multiple
modules, a test case ID may be identified by a module code and a serial number.
The following is a sample requirements traceability matrix.
The following is sample test execution data.
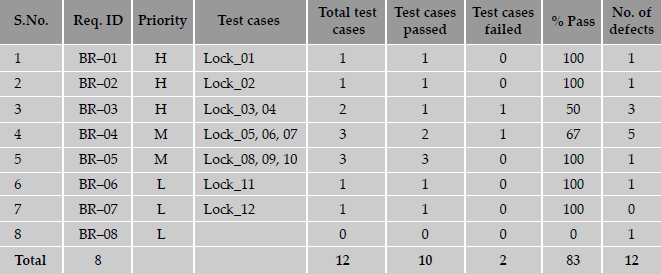
From the above table, the following observations can be made with respect to the requirements.
- 83 percent passed test cases correspond to 71 percent of requirements being met (five out of seven requirements met; one requirement not implemented). Similarly, from the failed test cases, outstanding defects affect 29 percent (= 100 - 71) of the requirements.
- There is a high-priority requirement, BR-03, which has failed. There are three corresponding defects that need to be looked into and some of them to be fixed and test case Lock_04 need to be executed again for meeting this requirement. Please note that not all the three defects may need to be fixed, as some of them could be cosmetic or low-impact defects.
- There is a medium-priority requirement, BR-04, has failed. Test case Lock_06 has to be re-executed after the defects (five of them) corresponding to this requirement are fixed.
- The requirement BR-08 is not met; however, this can be ignored for the release, even though there is a defect outstanding on this requirement, due to the low-priority nature of this requirement.
Once the test case creation is completed, the RTM helps in identifying the relationship between the requirements and test cases.
The following combinations are possible.
- One to one - For each requirement there is one test case (for example, BR-01)
- One to many - For each requirement there are many test cases (for example, BR-03)
- Many to one - A set of requirements can be tested by one test case (not represented in Table 4.2)
- Many to many - Many requirements can be tested by many test cases (these kind of test cases are normal with integration
and system testing; however, an RTM is not meant for this purpose)
- One to none - The set of requirements can have no test cases. The test team can take a decision not to test a requirement
due to non-implementation or the requirement being low priority (for example, BR-08)
A requirement is subjected to multiple phases of testing - unit, component, integration, and system testing. This reference to the
phase of testing can be provided in a column in the Requirements Traceability Matrix. This column indicates when a requirement will
be tested and at what phase of testing it needs to be considered for testing.
Requirements based testing tests the product's compliance to the requirements specifications. Once the test cases are executed,
the test results can be used to collect metrics such as
- Total number of test cases (or requirements) passed - Once test execution is completed, the total passed test cases and what
percent of requirements they correspond.
- Total number of test cases (or requirements) failed - Once test execution is completed, the total number of failed test cases
and what percent of requirements they correspond.
- Total number of defects in requirements - List of defects reported for each requirement (defect density for requirements). This
helps in doing an impact analysis of what requirements have more defects and how they will impact customers. A comparatively
high-defect density in low-priority requirements is acceptable for a release. A high-defect density in high-priority requirement
is considered a high-risk area, and may prevent a product release.
- Number of requirements completed - Total number of requirements successfully completed without any defects.
- Number of requirements pending - Number of requirements that are pending due to defects.
Boundary Value Analysis
Conditions and boundaries are two major sources of defects in a software product. Most of the defects in software products
hover around conditions and boundaries. By conditions, we mean situations wherein, based on the values of various variables,
certain actions would have to be taken. By boundaries, we mean limits of values of the various variables.
Boundary value analysis believes and extends the concept that the density of defect is more towards the boundaries.
Generally, defects in that happen around the boundaries might be due to the following.
- Programmers' tentativeness in using the right comparison operator, for example, whether to use the ≤ operator or < operator
when trying to make comparisons.
- Confusion caused by the availability of multiple ways to implement loops and condition checking. For example, in a programming
language like C, we have for loops, while loops and repeat loops. Each of these have different terminating conditions for the
loop and this could cause some confusion in deciding which operator to use, thus skewing the defects around the boundary conditions.
- The requirements themselves may not be clearly understood, especially around the boundaries, thus causing even the correctly coded
program to not perform the correct way.
Another instance where boundary value testing is extremely useful in uncovering defects is when there are internal limits placed
on certain resources, variables, or data structures. As an example, let us look at buffer management. there are four possible cases
to be tested - first, when the buffers are completely empty (this may look like an oxymoron statement!); second, when inserting buffers,
with buffers still free; third, inserting the last buffer, and finally, trying to insert when all buffers are full. It is likely that
more defects are to be expected in the last two cases than the first two cases.
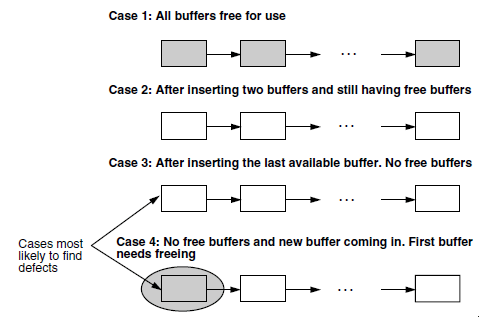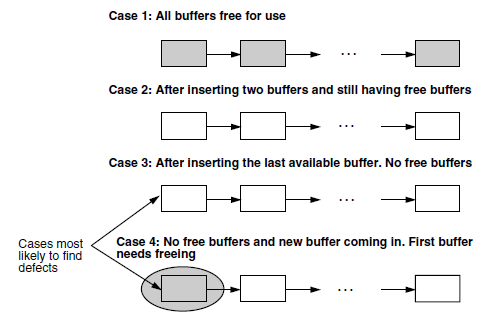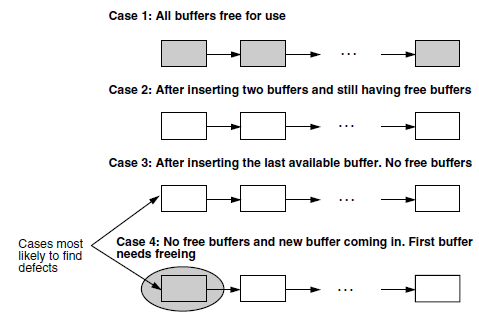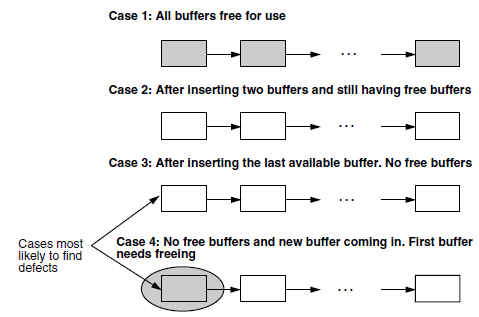
To summarize boundary value testing:
- Look for any kind of gradation or discontinuity in data values which affect computation - the discontinuities are the boundary values,
which require thorough testing.
- Look for any internal limits such as limits on resources (as in the example of buffers given above). The behavior of the product at these
limits should also be the subject of boundary value testing.
- Also include in the list of boundary values, documented limits on hardware resources. For example, if it is documented that a product will
run with minimum 4MB of RAM, make sure you include test cases for the minimum RAM (4MB in this case).
- The examples given above discuss boundary conditions for input data - the same analysis needs to be done for output variables also.
Decision Tables
A decision table lists the various decision variables, the conditions (or values) assumed by each of the decision variables, and the actions
to take in each combination of conditions. The variables that contribute to the decision are listed as the columns of the table. The last
column of the table is the action to be taken for the combination of values of the decision variables. In cases when the number of decision
variables is many (say, more than five or six) and the number of distinct combinations of variables is few (say, four or five), the decision
variables can be listed as rows (instead of columns) of the table.
The steps in forming a decision table are as follows.
- Identify the decision variables.
- Identify the possible values of each of the decision variables.
- Enumerate the combinations of the allowed values of each of the variables.
- Identify the cases when values assumed by a variable (or by sets of variables) are immaterial for a given combination of other input
variables. Represent such variables by the don't care symbol.
- For each combination of values of decision variables (appropriately minimized with the don't care scenarios), list out the action or
expected result.
- Form a table, listing in each but the last column a decision variable. In the last column, list the action item for the combination
of variables in that row (including don't cares, as appropriate).
A decision table is useful when input and output data can be expressed as Boolean conditions (TRUE, FALSE, and DON'T CARE).
Once a decision table is formed, each row of the table acts as the specification for one test case. Identification of the decision variables
makes these test cases extensive, if not exhaustive. Pruning the table by using don't cares minimizes the number of test cases. The following
is a decision table for calculating the standard deduction from your income tax. Most taxpayers have a choice of either taking a standard
deduction or itemizing their deductions. The standard deduction is a dollar amount that reduces the amount of income on which you are taxed.
It is a benefit that eliminates the need for many taxpayers to itemize actual deductions, such as medical expenses, charitable contributions,
and taxes. The standard deduction is higher for taxpayers who are 65 or older or blind. If you have a choice, you should use the method that
gives you the lower tax.
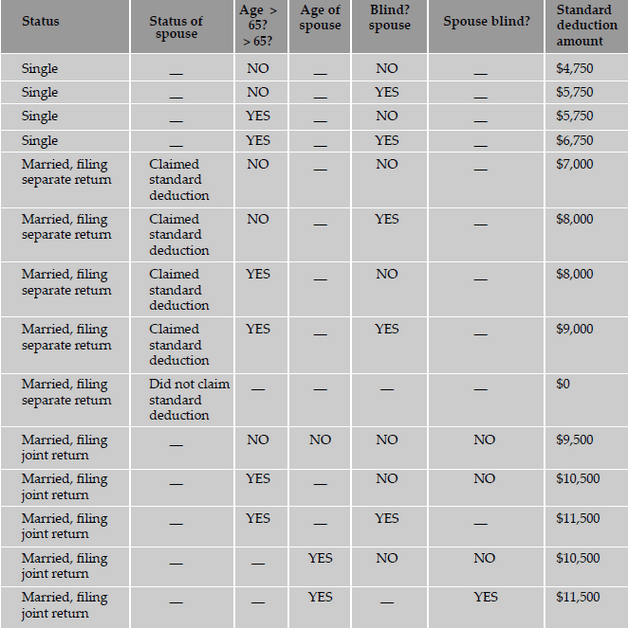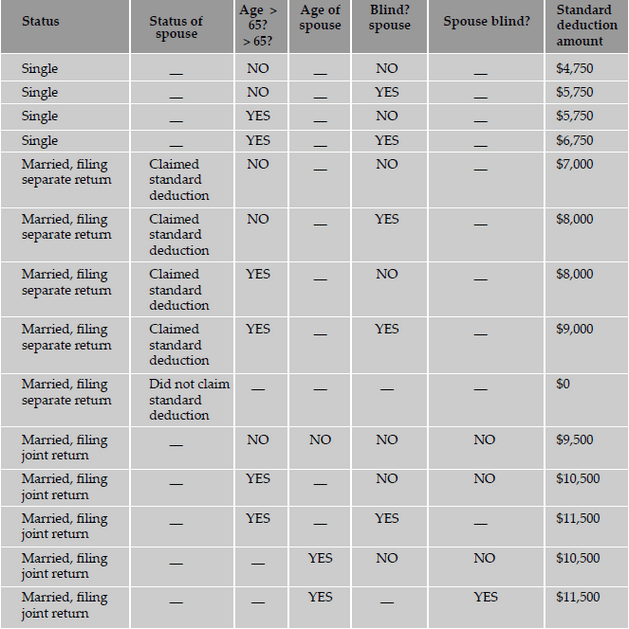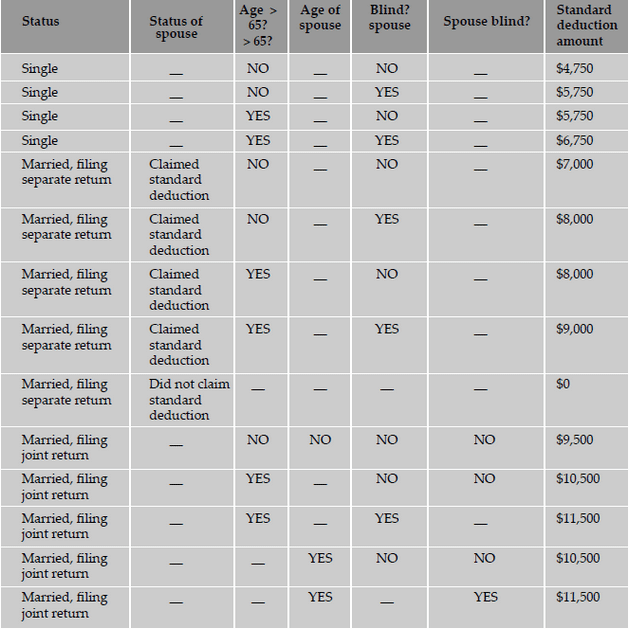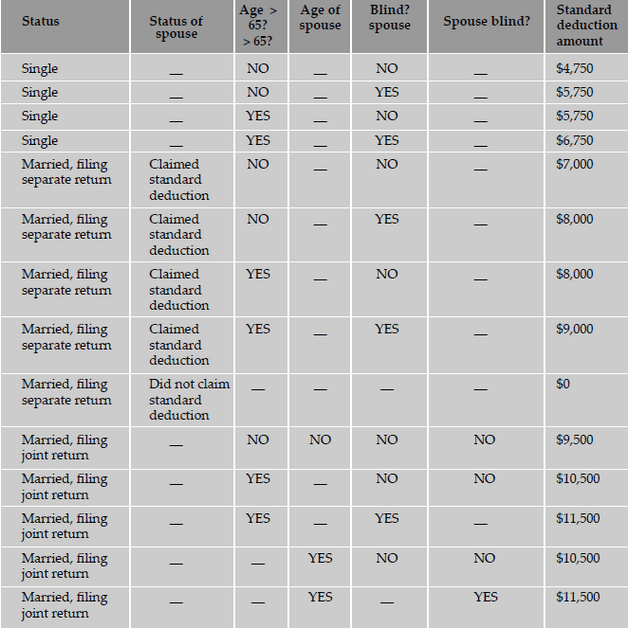
Thus, decision tables act as invaluable tools for designing black box tests to examine the behavior of the product under various logical
conditions of input variables. The steps in forming a decision table are as follows.
- Identify the decision variables.
- Identify the possible values of each of the decision variables.
- Enumerate the combinations of the allowed values of each of the variables.
- Identify the cases when values assumed by a variable (or by sets of variables) are immaterial for a given combination of other input variables. Represent such variables by the don't care symbol.
- For each combination of values of decision variables (appropriately minimized with the don't care scenarios), list out the action or expected result.
- Form a table, listing in each but the last column a decision variable. In the last column, list the action item for the combination of variables in that row (including don't cares, as appropriate).
Equivalence Partitioning
Equivalence partitioning is a software testing technique that involves identifying a small set of representative input values that produce
as many different output conditions as possible. This reduces the number of permutations and combinations of input, output values used for
testing, thereby increasing the coverage and reducing the effort involved in testing.
The set of input values that generate one single expected output is called a partition. When the behavior of the software is the same
for a set of values, then the set is termed as an equivalance class or a partition. In this case, one representative sample from
each partition (also called the member of the equivalance class) is picked up for testing. One sample from the partition is enough for testing
as the result of picking up some more values from the set will be the same and will not yield any additional defects. Since all the values
produce equal and same output they are termed as equivalance partition. Testing by this technique involves (a) identifying all partitions for
the complete set of input, output values for a product and (b) picking up one member value from each partition for testing to maximize complete
coverage. From the results obtained for a member of an equivalence class or partition, this technique extrapolates the expected results for all
the values in that partition. The advantage of using this technique is that we gain good coverage with a small number of test cases. The below
shows the equivalence classes for life insurance premiums.
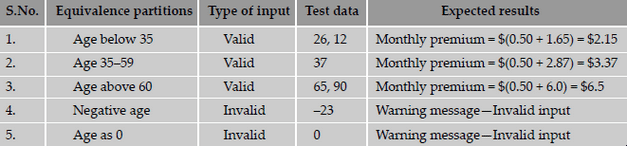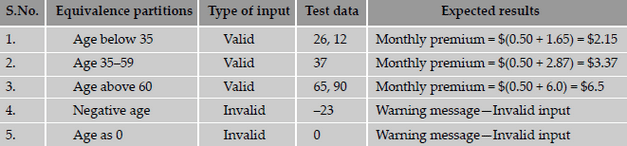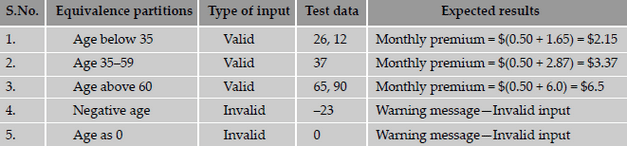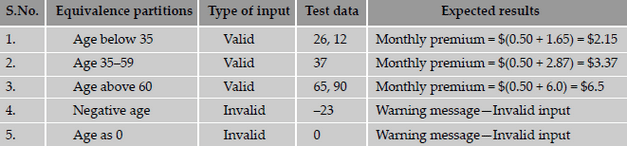
The steps to prepare an equivalence partitions table are as follows.
- Choose criteria for doing the equivalence partitioning (range, list of values, and so on)
- Identify the valid equivalence classes based on the above criteria (number of ranges allowed values, and so on)
- Select a sample data from that partition
- Write the expected result based on the requirements given
- Identify special values, if any, and include them in the table
- Check to have expected results for all the cases prepared
- If the expected result is not clear for any particular test case, mark appropriately and escalate for corrective
actions. If you cannot answer a question, or find an inappropriate answer, consider whether you want to record this
issue on your log and clarify with the team that arbitrates/dictates the requirements.
State Based or Graph Based Testing
State or graph based testing is very useful in situations where
- The product under test is a language processor (for example, a compiler), wherein the syntax of the language automatically lends itself to a
state machine or a context free grammar represented by a railroad diagram.
- Workflow modeling where, depending on the current state and appropriate combinations of input variables, specific workflows are carried out,
resulting in new output and new state.
- Dataflow modeling, where the system is modeled as a set of dataflow, leading from one state to another.
A general outline for using state based testing methods with respect to language processors is:
- Identify the grammar for the scenario. In the above example, we have represented the diagram as a state machine. In some cases, the scenario
can be a context-free grammar, which may require a more sophisticated representation of a "state diagram."
- Design test cases corresponding to each valid state-input combination.
- Design test cases corresponding to the most common invalid combinations of state-input.
Graph based testing will be applicable when
- The application can be characterized by a set of states.
- The data values (screens, mouse clicks, and so on) that cause the transition from one state to another is well understood.
- The methods of processing within each state to process the input received is also well understood.
Compatibility Testing
The test case results not only depend on the product for proper functioning; they depend equally on the infrastructure for delivering
functionality. When infrastructure parameters are changed, the product is expected to still behave correctly and produce the desired or
expected results. The infrastructure parameters could be of hardware, software, or other components. These parameters are different for
different customers. A black box testing, not considering the effects of these parameters on the test case results, will necessarily be
incomplete and ineffective, as it may not truly reflect the behavior at a customer site. Hence, there is a need for compatibility testing.
This testing ensures the working of the product with different infrastructure components.
The parameters that generally affect the compatibility of the product are
- Processor (CPU) (Pentium III, Pentium IV, Xeon, SPARC, and so on) and the number of processors in the machine
- Architecture and characterstics of the machine (32 bit, 64 bit, and so on)
- Resource availability on the machine (RAM, disk space, network card)
- Equipment that the product is expected to work with (printers, modems, routers, and so on)
- Operating system (Windows, Linux, and so on and their variants) and operating system services (DNS, NIS, FTP, and so on)
- Middle-tier infrastructure components such as web server, application server, network server
- Backend components such database servers (Oracle, Sybase, and so on)
- Services that require special hardware/software solutions (cluster machines, load balancing, RAID array, and so on)
- Any software used to generate product binaries (compiler, linker, and so on and their appropriate versions)
- Various technological components used to generate components (SDK, JDK, and so on and their appropriate different versions)
The above are just a few of the parameters. There are many more parameters that can affect the behavior of the product features.
In order to arrive at practical combinations of the parameters to be tested, a compatibility matrix is created. A compatibility
matrix has as its columns various parameters the combinations of which have to be tested. Each row represents a unique combination
of a specific set of values of the parameters. A sample compatibility matrix for a mail application is shown below.
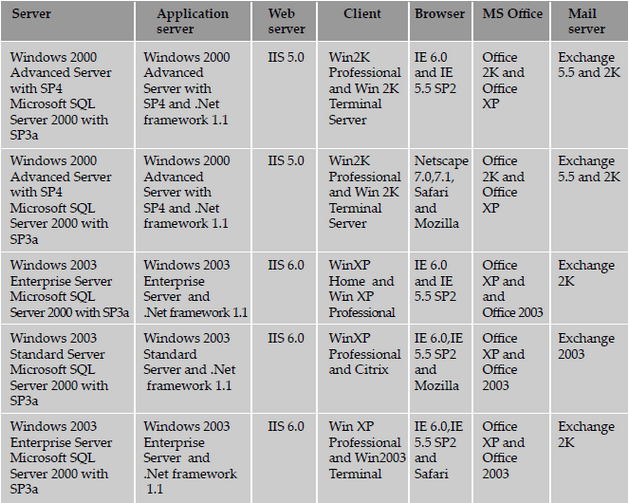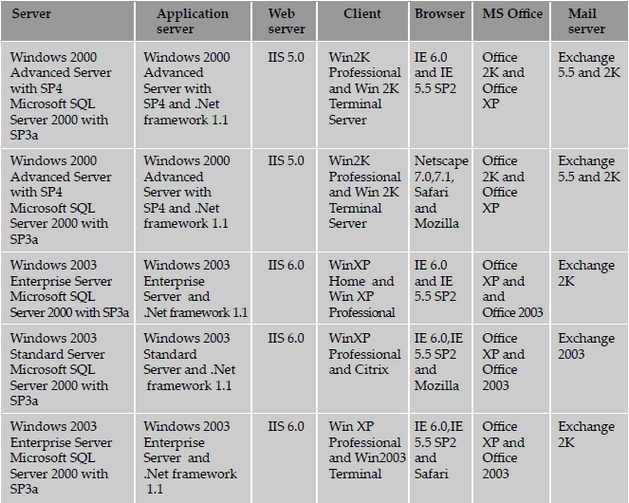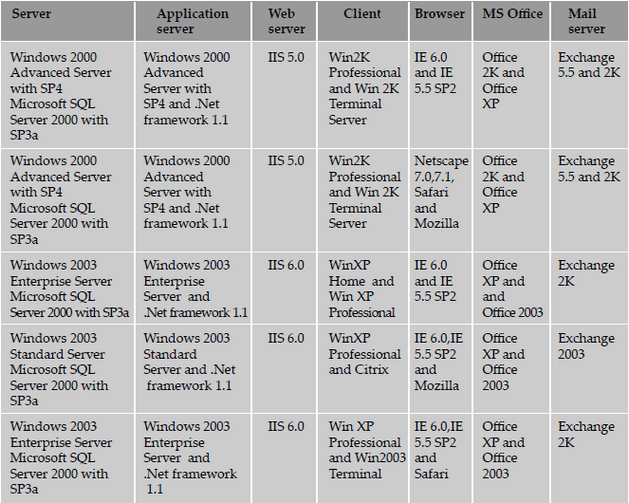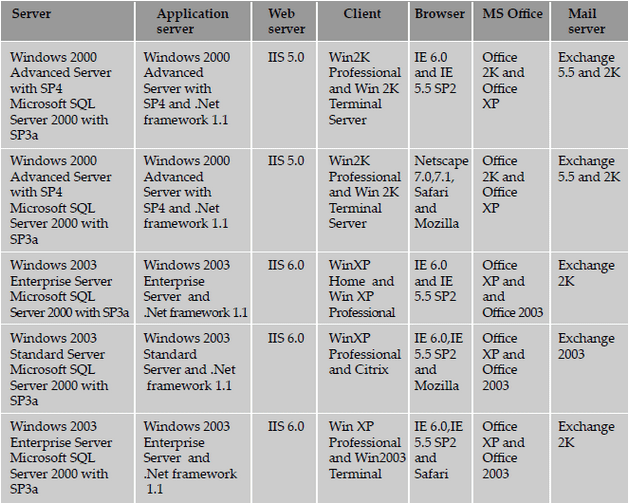
Some of the common techniques that are used for performing compatibility testing, using a compatibility table are
- Horizontal combination All values of parameters that can coexist with the product for executing the set test cases are
grouped together as a row in the compatibility matrix. The values of parameters that can coexist generally belong to different
layers/types of infrastructure pieces such as operating system, web server, and so on. Machines or environments are set up for
each row and the set of product features are tested using each of these environments.
- Intelligent sampling In the horizontal combination method, each feature of the product has to be tested with each row
in the compatibility matrix. This involves huge effort and time. To solve this problem, combinations of infrastructure parameters
are combined with the set of features intelligently and tested. When there are problems due to any of the combinations then the
test cases are executed, exploring the various permutations and combinations. The selection of intelligent samples is based on
information collected on the set of dependencies of the product with the parameters. If the product results are less dependent
on a set of parameters, then they are removed from the list of intelligent samples. All other parameters are combined and tested.
This method significantly reduces the number of permutations and combinations for test cases.
Compatibility testing not only includes parameters that are outside the product, but also includes some parameters that are a
part of the product. For example, two versions of a given version of a database may depend on a set of APIs that are part of the
same database. These parameters are also an added part of the compatibility matrix and tested. The compatibility testing of a
product involving parts of itself can be further classified into two types.
- Backward compatibility testing There are many versions of the same product that are available with the customers. It
is important for the customers that the objects, object properties, schema, rules, reports, and so on, that are created with
an older version of the product continue to work with the current version of the same product. The testing that ensures the
current version of the product continues to work with the older versions of the same product is called backwad compatibility
testing. The product parameters required for the backward compatibility testing are added to the compatibility matrix and are
tested.
- Forward compatibility testing There are some provisions for the product to work with later versions of the product
and other infrastructure components, keeping future requirements in mind. For example, IP network protocol version 6 uses 128
bit addressing scheme (IP version 4, uses only 32 bits). The data structures can now be defined to accommodate 128 bit addresses,
and be tested with prototype implementation of Ipv6 protocol stack that is yet to become a completely implemented product. The
features that are part of Ipv6 may not be still available to end users but this kind of implementation and testing for the future
helps in avoiding drastic changes at a later point of time. Such requirements are tested as part of forward compatibily testing.
Testing the product with a beta version of the operating system, early access version of the developers' kit, and so on are examples
of forward compatibility. This type of testing ensures that the risk involved in product for future requirements is minimized.
User Documentation Testing
User documentation covers all the manuals, user guides, installation guides, setup guides, read me file, software release notes, and
online help that are provided along with the software to help the end user to understand the software system. When a product is upgraded,
the corresponding product documentation should also get updated as necessary to reflect any changes that may affect a user. However,
this does not necessarily happen all the time. One of the factors contributing to this may be lack of sufficient coordination between
the documentation group and the testing/development groups. Over a period of time, product documentation diverges from the actual behavior
of the product. User documentation testing focuses on ensuring what is in the document exactly matches the product behavior, by sitting in
front of the system and verifying screen by screen, transaction by transaction and report by report. In addition, user documentation testing
also checks for the language aspects of the document like spell check and grammar.
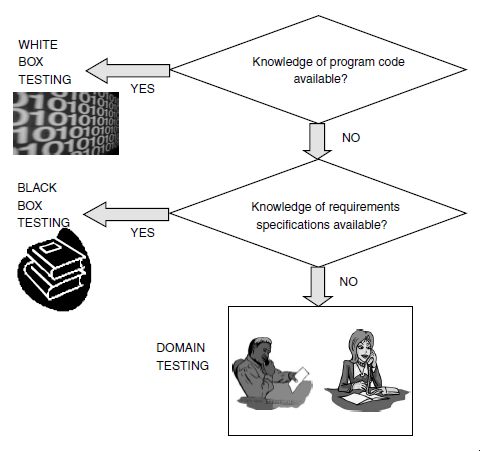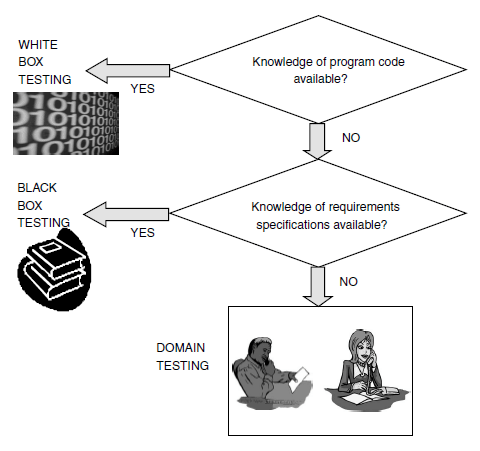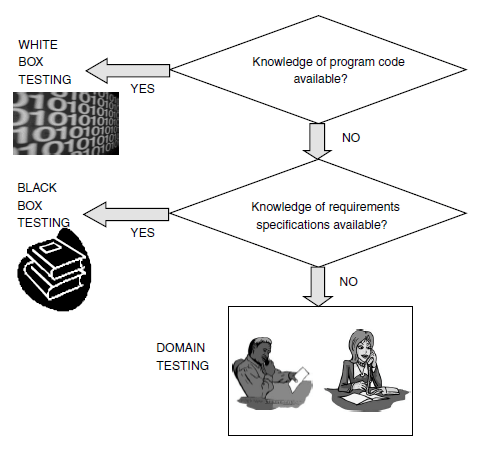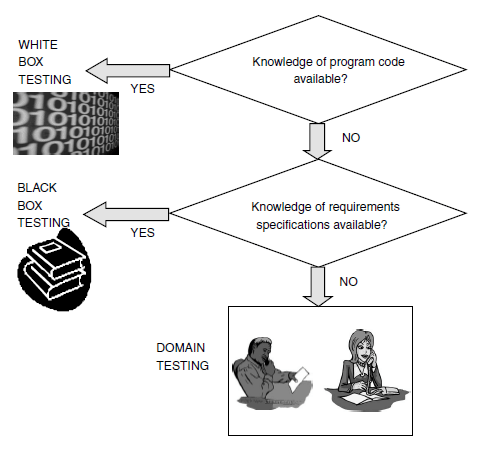
Domain Testing
Domain testing can be considered as the next level of testing in which we do not look even at the specifications of a software product
but are testing the product, purely based on domain knowledge and expertise in the domain of application. This testing approach requires
critical understanding of the day-to-day business activities for which the software is written. This type of testing requires business
domain knowledge rather than the knowledge of what the software specification contains or how the software is written. Thus domain
testing can be considered as an extension of black box testing. As we move from white box testing through black box testing to domain
testing we know less and less about the details of the software product and focus more on its external behavior.
The test engineers performing this type of testing are selected because they have in-depth knowledge of the business domain. Since the
depth in business domain is a prerequisite for this type of testing, sometimes it is easier to hire testers from the domain area (such
as banking, insurance, and so on) and train them in software, rather than take software professionals and train them in the business
domain. This reduces the effort and time required for training the testers in domain testing and also increases the effectivenes of
domain testing.
Domain testing is the ability to design and execute test cases that relate to the people who will buy and use the software. It helps
in understanding the problems they are trying to solve and the ways in which they are using the software to solve them. It is also
characterized by how well an individual test engineer understands the operation of the system and the business processes that system
is supposed to support. If a tester does not understand the system or the business processes, it would be very difficult for him or
her to use, let alone test, the application without the aid of test scripts and cases.
Summary
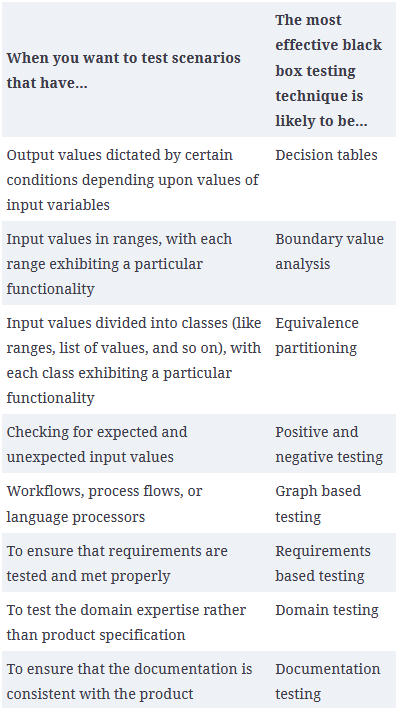
The below table summarizes the scenarios under which each of the black-box techniques will be useful. By judiciously mixing and
matching these different techniques, the overall costs of other tests done downstream, such as integration testing, system testing,
and so on, can be reduced.
Problems and Exercises
We will complete the following problems and exercises during lecture or during lab time.
- Consider the lock and key example discussed in the text. We had assume that there is only one key for the lock. Assume that the lock requires
two keys to be inserted in a particular order. Modify the sample requirements given in the first table to take care of this condition. Correspondingly,
create the Traceability Matrix akin to what is in the second table.
- In each of the following cases, identify the most appropriate black box testing technique that can be used to test the following requirements:
- "The valid values for the gender code are 'M' or 'F'."
- "The number of days of leave per year an employee is eligible is 10 for the first three years, 15 for the next two years, and 20 from then on."
- "Each purchase order must be initially approved by the manager of the employee and the head of purchasing. Additionally, if it is a capital expense
of more than $10,000, it should also be approved by the CFO."
- "A file name should start with an alphabetic character, can have up to 30 alphanumeric characters, optionally one period followed by up to 10 other
alphanumeric characters."
- "A person who comes to bank to open the account may not have his birth certificate in English; in this case, the officer must have the discretion
to manually override the requirement of entering the birth certificate number."
- Consider the example of deleting an element from a linked list. What are the boundary
value conditions? Identify test data to test at and around boundary values.
- A web-based application can be deployed on the following environments:
- OS (Windows and Linux)
- Web server (IIS 5.0 and Apache)
- Database (Oracle, SQL Server)
- Browser (IE 6.0 and Firefox)
How many configurations would you have to test if you were to exhaustively test all the combinations? What criteria would you use to prune the above list?
- A product is usually associated with different types of documentation - installation document (for installing the product), administration document, user
guide, etc. What would be the skill sets required to test these different types of documents? Who would be best equipped to do each of these testing?
- An input value for a product code in an inventory system is expected to be present in a product master table. Identify the set of equivalence classes to
test these requirements.
- In the book, we discussed examples where we partitioned the input space into multiple equivalence classes. Identify situations where the equivalence classes
can be obtained by partitioning the output classes.
- A sample rule for creating a table in a SQL database is given below: The statement should start with the syntax
CREATE TABLE <table name>
This should be followed by an open parenthesis, a comma separated list of column identifiers. Each column identifier should have a mandatory
column name, a mandatory column type (which should be one of NUMER, CHAR, and DATE) and an optional column width. In addition, the rules dictate:
- Each of the key words can be abbreviated to 3 characters or more
- The column names must be unique within a table
- The table names should not be repeated.
For the above set of requirements, draw a state graph to derive the initial test cases. Also use other techniques like appropriate to check a-c above.
Possibly answers to the weekly exercises can be found here.